Saviez vous que les fichiers Parquet se prenaient pour des bombes ? Alors pas des bombes latines mais plutôt des bombes zip.
Alors, pour ceux qui débarquent de la planète Mars, il faut savoir que Parquet est devenu le format de prédilection pour échanger des données tabulaires. Très utilisé dans tout ce qui est Big Data et qui met une claque à ce bon vieux CSV tout pourri, Parquet, c’est binaire, c’est colonnaire, c’est compressé, c’est top !
Mais attention, derrière cette apparente perfection se cache un danger mortel pour vos disques durs et autres SSD ! En effet, même un fichier Parquet parfaitement valide peut mettre un sacré bordel et faire planter tous vos services.
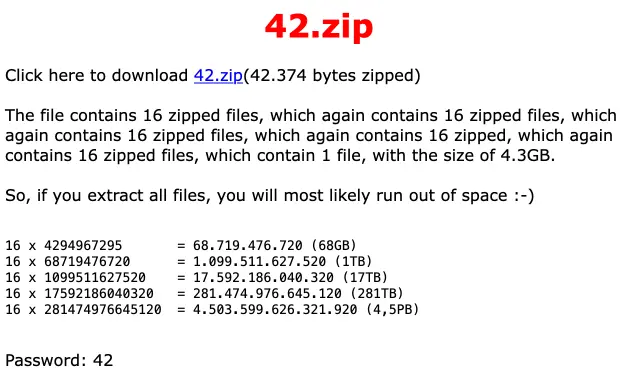
Comment ? Et bien simplement avec ce fichier de seulement 42 Ko qui contient… tenez-vous bien… plus de 4 PÉTAOCTETS de données !! Oui, on parle bien de 4 millions de gigaoctets dans un malheureux fichier de 42 Ko, fallait oser.
Eh bien c’est grâce à un petit tour de passe-passe démoniaque appelé « encodage par dictionnaire« . En gros, on lui donne un dictionnaire avec une seule valeur, et ensuite on fait référence à cette valeur en boucle, environ 2 milliards de fois. Résultat, on obtient un fichier minuscule car compressable au maximum mais qui une fois dézippé représente une table monstrueusement gigantesque.
C’est subtil… mais c’est vicieux ! 😈
Imaginez un peu le carnage si vous balancez ce fichier innocent dans votre pipeline Big Data sans faire gaffe… Boom ! 💥 Plantage général, crash systémique, apocalypse nucléaire ! Vos services vont tenter de lire ce fichier en pensant que c’est un gentil petit fichier Parquet de rien du tout, et là… Surprise ! C’est le chaos total. Votre cluster va fondre comme neige au soleil en essayant d’avaler ces pétaoctets de données.
Morale de l’histoire, faites attention à tout, même à ce que vous dézippez.
Et si vous avez un peu de place sur votre disque dur, vous pouvez toujours tenter l’aventure en téléchargeant 42.zip ici. (NON, NE DEZIPPEZ PAS CE TRUC !! MAUVAISE IDEE !!) (le mot de passe du zip est : 42)
In the early 2010s, Apache Hadoop captured the imagination of the tech community. A free and powerful open source platform, it gave users a way to process unimaginably large quantities of data, and offered a dazzling variety of tooling to suit nearly every use case – MapReduce for odd jobs like processing of text, audio or video; Hive for SQL based data warehousing; Pig, an unusual language with a similar data warehousing goal; Hbase, Oozie, Sqoop, Flume and a whole parade of other tools for processing massive datasets at scale.
With the surge in interest in Hadoop, a number of startups and established software companies jumped to provide commercial offerings of it. Cloudera was one of the first into the game with CDH – a Hadoop distribution. Initially offered as Deb packages and RPMs, Cloudera quickly introduced Cloudera Manager, a sophisticated, web-based management system to deploy, maintain, and operate Hadoop clusters. With the introduction of Cloudera Manager, Cloudera established themselves as the market leader. Over time, they consolidated their position, merging with competitor HortonWorks.
A lot has changed in the nearly two decades since Hadoop’s release
Hadoop was designed and built as a hyperscale system to be deployed on premise in the data centre, well before public cloud computing had established its dominance and become arguably the most popular way to deliver IT services.
Certain design assumptions taken with Hadoop, like the paradigm “bring the compute to the data”, made sense in the context of a millennial data centre, with 1GbE networking and a relatively low cost per GB for direct attached storage media. But many of those design assumptions make little sense on the cloud, where local block storage devices are costly versus remote, highly durable object storage – which is offered with a far lower cost per GB.
Then there were parts of Hadoop’s critical architecture – for instance YARN and Kerberos – which over time proved to be difficult to work with. YARN is a complex cluster job scheduler with a narrow focus on data processing, whilst the Kerberos security protocol used by Hadoop has long been a bugbear for many administrators.
In short: Hadoop was never designed with cloud computing in mind.
Between the ageing architecture and the complexity of the platform, many are looking to make a move away from Hadoop and from Cloudera, and seek a state-of-the-art alternative, more aligned with modern cloud-native computing principles and optimised for low cost operation in the contemporary cloud context.
Cloudera migration alternatives
When architects are looking for alternative data hub platforms, they tend to seek a solution that’s free, open source, powerful, and flexible. Like Hadoop, it should be capable of processing extremely large quantities of data, and give them flexibility in features to suit a wide array of use cases. But these days, the solution needs to be cloud ready, capable of auto scaling, and must run efficiently with a low operational cost.
Charmed Spark from Canonical is founded on Apache Spark, a mature and sophisticated data processing framework widely used with Hadoop. Spark supports data engineering, data lakehouse, and data science use cases for AI/ML and has been widely adopted by the Big Data user community. Charmed Spark entirely replaces Hadoop YARN with the more general purpose, extensible cluster resource manager – Kubernetes. Kubernetes has become by far the most popular cluster resource manager on the market today, with a flexible palette of features and plugins.
How to move legacy workloads off Hadoop
You’re leaving 2010 behind, but you aren’t giving up its data – nor its processing logic. You need to make sure that your chosen migration plan makes it relatively straightforward to bring all of it with you. In our experience, this has been a major concern for clients planning a data hub migration to a modern, cloud-native infrastructure, and it’s why Charmed Spark is designed to offer a straightforward path from legacy Hadoop to a state-of-the-art, cloud-native data platform.
Charmed Spark includes a distribution of Apache Spark – the most popular of the Hadoop data processing frameworks – designed and built to run on Kubernetes. It offers an effective replacement for Hadoop, as its architecture entirely supersedes YARN and abstracts away the data storage tier to cloud object storage. Legacy Hadoop workloads such as Hive-based SQL data processing applications can often be readily migrated to the Spark framework, which has a high degree of compatibility with Hive, simplifying the transition from Hadoop. Charmed Spark is also available as a fully integrated offer for the data centre, including the Ceph object storage system and an advanced Kubernetes distribution from Canonical, easing transition from legacy Hadoop still further.
How to maintain flexibility in your cloud-native data hub design
A modern data hub is nothing if it lacks connectivity to popular object storage systems on the cloud. Whether it’s AWS S3, Azure Data Lake Store, Google Cloud Storage, or API compatible clones, a flexible data hub needs to be able to access and use all of these systems. Charmed Spark has been built with this in mind.
Architects are also concerned with workload consolidation and efficiency and with this in mind, the solution offers support for the Volcano gang scheduler Kubernetes plugin, helping ensure maximum efficiency on the Kubernetes cluster.
Cloud lock-in remains a worry for many, and a key concern that a modern data hub architecture needs to address. Charmed Spark offers platform portability between clouds. The solution can be deployed to many popular cloud Kubernetes platforms, including AWS EKS and Google GKE.
Cloudera migration: how to migrate while keeping costs manageable
One of the biggest pressure points in a migration project is cost, and it’s often the deciding factor in new technology adoption, even beyond functionality. Like Hadoop, Charmed Spark ticks both boxes – cost and capability – as it’s free to deploy and use.
As with any other project, the cost concern is a long-term consideration: how do you keep your data hub secure, up to date, and protected, in a cost-effective manner? Charmed Spark offers long-term support and security maintenance commitments: the Charmed Spark solution is available with up to ten years of support per stable track – which includes security fixes and break/fix support with a choice of 24/7 or weekday SLA.