Ventana and Canonical collaborate on enabling enterprise data center, high-performance and AI computing on RISC-V
This blog is co-authored by Gordan Markuš, Canonical and Kumar Sankaran, Ventana Micro Systems
Unlocking the future of semiconductor innovation
RISC-V, an open standard instruction set architecture (ISA), is rapidly shaping the future of high-performance computing, edge computing, and artificial intelligence. The RISC-V customizable and scalable ISA enables a new era of processor innovation and efficiency. Furthermore, RISC-V democratizes innovation by allowing new companies to develop their own products on its open ISA, breaking down barriers to entry and fostering a diverse ecosystem of technological advancement.
By fostering a more open and innovative approach to product design, the RISC-V technology vendors are not just a participant in the future of technology; they are a driving force behind the evolution of computing across multiple domains. Its impact extends from the cloud to the edge:
- In modern data centers, enterprises seek a range of infrastructure solutions to support the breadth of modern workloads and requirements. RISC-V provides a versatile solution, offering a comprehensive suite of IP cores under a unified ISA that scales efficiently across various applications. This scalability and flexibility makes RISC-V an ideal foundation for addressing the diverse demands of today’s data center environments.
- In HPC, its adaptability allows for the creation of specialized processors that can handle complex computations at unprecedented speeds, while also offering a quick time to market for product builders.
- For edge computing, RISC-V’s efficiency and the ability to tailor processors for specific tasks mean devices can process more data locally, reducing latency and the need for constant cloud connectivity.
- In the realm of AI, the flexibility of RISC-V paves the way for the development of highly optimized AI chips. These chips can accelerate machine learning tasks by executing AI centric computations more efficiently, thus speeding up the training and inference of AI workloads.
One of the unique products that can be designed with RISC-V ISA are chiplets. Chiplets are smaller, modular blocks of silicon that can be integrated to form a larger, more complex chip. Instead of designing a single monolithic chip, a process that is increasingly challenging and expensive at cutting-edge process nodes, manufacturers can create chiplets that specialize in different functions and combine them as needed. RISC-V and chiplet technology is empowering a new era of chip design, enabling more companies to participate in innovation and tailor their products to specific market needs with unprecedented flexibility and cost efficiency.
Ventana and Canonical partnership and technology leadership
Canonical makes open source secure, reliable and easy to use, providing support for Ubuntu and a growing portfolio of enterprise-grade open source technologies. One of the key missions of Canonical is to improve the open source experience across ISA architectures. At the end of 2023, Canonical announced joining the RISC-V Software Ecosystem (RISE) community to support the open source community and ecosystem partners in bringing the best of Ubuntu and open source to RISC-V platforms.
As a part of our collaboration with the ecosystem, Canonical has been working closely with Ventana Micro Systems (Ventana). Ventana is delivering a family of high-performance RISC-V data center-class CPUs delivered in the form of multi-core chiplets or core IP for high-performance applications in the cloud, enterprise data center, hyperscale, 5G, edge compute, AI/ML and automotive markets.
The relationship between Canonical and Ventana started with a collaboration on improving the upstream software availability of RISC-V in projects such as u-boot, EDKII and the Linux kernel.
Over time, the teams have started enabling Ubuntu on Ventana’s Veyron product family. Through the continuous efforts of this partnership Ubuntu is available on the Ventana Veyron product family and as a part of Ventana’s Veyron Software Development Kit (SDK).
Furthermore, the collaboration extends to building full solutions for the datacenter, HPC, AI/ML and Automotive, integrating Domain Specific Accelerators (DSAs) and SDKs, promising to unlock new levels of performance and efficiency for developers and enterprises alike. Some of the targeted software stacks can be seen in the figure below.
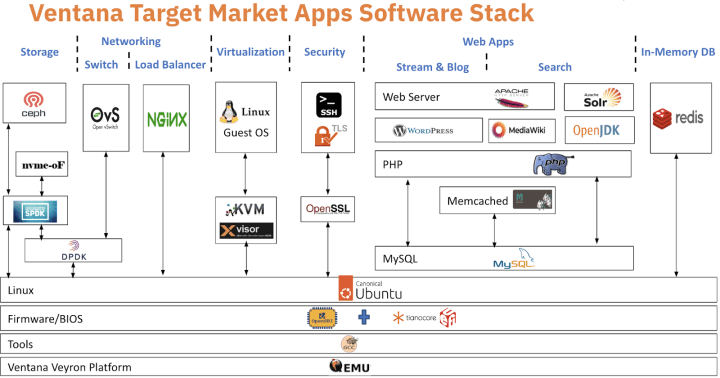
Today, Ventana and Canonical collaborate on a myriad of topics. Together through their joint efforts across open source communities and as a part of RISC-V Software Ecosystem (RISE), Ventana and Canonical are actively contributing to the growth of the RISC-V ecosystem. We are proud of the innovation and technology leadership our partnership brings to the ecosystem.
Enabling the ecosystem with enterprise-grade and easy to consume open source on RISC-V platforms
Ubuntu is the reference OS for innovators and developers, but also the vehicle to enable enterprises to take products to market faster. Ubuntu enables teams to focus on their core applications without worrying about the stability of the underlying frameworks. Ventana and the RISC-V ecosystem recognise the value of Ubuntu and are using it as a base platform for their innovation.
Furthermore, the availability of Ubuntu on RISC-V platforms not only allows developers to prototype their solutions easily but provides a path to market with enterprise-grade, secure and supported open source solutions.Whether it’s for networking offloads in the data center, training AI models in the cloud, or running AI inference at the edge, Ubuntu is an established platform of choice.
Learn more about Canonical’s engagement in the RISC-V ecosystem
- Linux made easy on RISC-V with Ubuntu
- Demo: The Future of Ubuntu on RISC-V – Gordan Markus, Canonical
- Download Ubuntu for RISC-V Platforms
- Ubuntu continues expanding RISC-V enablement in 2022
- Silicon Programme | Partners
Contact Canonical to bring Ubuntu and open source software to your RISC-V platform.