Deploying Open Language Models on Ubuntu
This blog post explores the technical and strategic benefits of deploying open-source AI models on Ubuntu. We’ll highlight why it makes sense to use Ubuntu with open-source AI models, and outline the deployment process on Azure.
Authored by Gauthier Jolly, Software Engineer, CPC, and Jehudi Castro-Sierra, Public Cloud Alliance Director, both from Canonical.
Why Ubuntu for Open-Source AI?
- Open Philosophy: Ubuntu’s open-source nature aligns seamlessly with the principles of open-source AI models, fostering collaboration and accessibility.
- Seamless Integration: Deploying open-source AI is smooth on Ubuntu, thanks to its robust support for AI libraries and tools.
- Community: Ubuntu’s large community provides valuable resources and knowledge-sharing for AI development.
The Role of Ubuntu Pro
Ubuntu Pro elevates the security and compliance aspects of deploying AI models, offering extended security maintenance, comprehensive patching, and automated compliance features that are vital for enterprise-grade applications. Its integration with Confidential VMs on Azure enhances the protection of sensitive data and model integrity, making it an indispensable tool for tasks requiring stringent security measures like ML training, inference, and confidential multi-party data analytics.
Why use the public cloud for deploying AI models?
Using a public cloud like Azure gives straightforward access to powerful GPUs and Confidential Compute capabilities, essential for intensive AI tasks. These features significantly reduce the time and complexity involved in setting up and running AI models, without compromising on security and privacy. Although some may opt for on-prem deployment due to specific requirements, Azure’s scalable and secure environment offers a compelling argument for cloud-based deployments.
Provisioning and Configuration
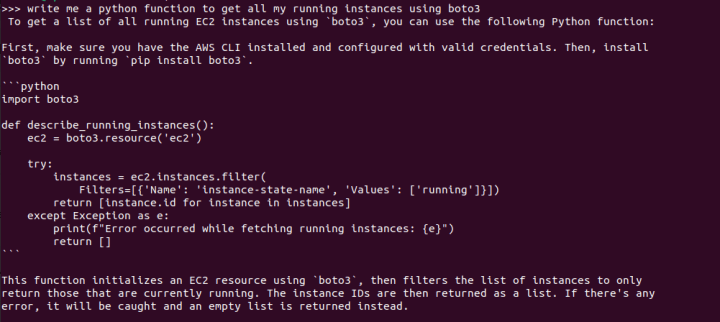
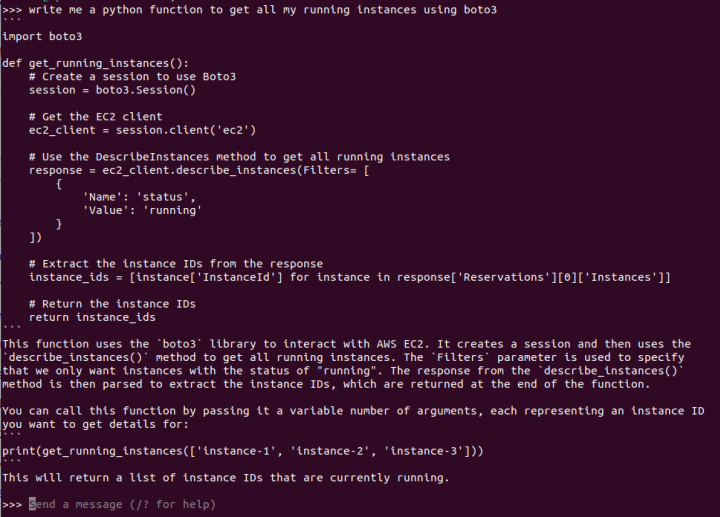
We are going to explore using open models on Azure by creating an instance with Ubuntu, installing NVIDIA drivers for GPU support, and setting up Ollama for running the models. The process is technical, involving CLI commands for creating the resource group, VM, and configuring NVIDIA drivers. Ollama, the chosen tool for running models like Mixtral, is best installed using Snap for a hassle-free experience, encapsulating dependencies and simplifying updates.
Provision an Azure VM
Begin by creating a resource group and then a VM with the Ubuntu image using the Azure CLI.
az group create --location westus --resource-group ml-workload
az vm create \
--resource-group ml-workload \
--name jammy \
--image Ubuntu2204 \
--generate-ssh-keys \
--size Standard_NC4as_T4_v3 \
--admin-username ubuntu --license-type UBUNTU_PRO
Note the publicIpAddress from the output – you’ll need it to SSH into the VM.
Install Nvidia Drivers (GPU Support)
For GPU capabilities, install NVIDIA drivers using Ubuntu’s package management system. Restart the system after installation.
sudo apt update -y sudo apt full-upgrade -y sudo apt install -y ubuntu-drivers-common sudo ubuntu-drivers install sudo systemctl reboot
Important: Standard NVIDIA drivers don’t support vGPUs (fractional GPUs). See instructions on the Azure site for installing GRID drivers, which might involve building an unsigned kernel module (which may be incompatible with Secure Boot).
Deploying Ollama with Snap
Snap simplifies the installation of Ollama and its dependencies, ensuring compatibility and streamlined updates. The –beta flag allows you to access the latest features and versions, which might still be under development
sudo snap install --beta ollama
Configuration
Configure Ollama to use the ephemeral disk
sudo mkdir /mnt/models sudo snap connect ollama:removable-media # to allow the snap to reach /mnt sudo snap set ollama models=/mnt/models
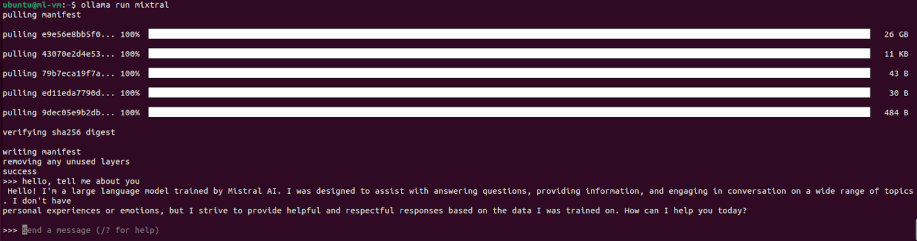
Installing Mixtral
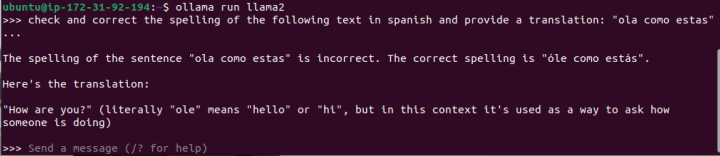
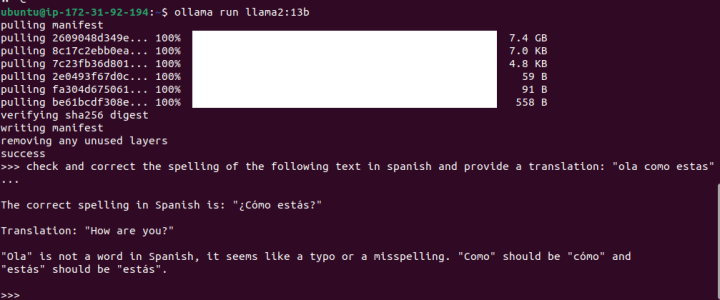
At this point, you can run one of the open models available out of the box, like mixtral or llama2. If you have a fine-tuned version of these models (a process that involves further training on a specific dataset), you can run those as well.
ollama run mixtral
The first run might take a while to download the model.
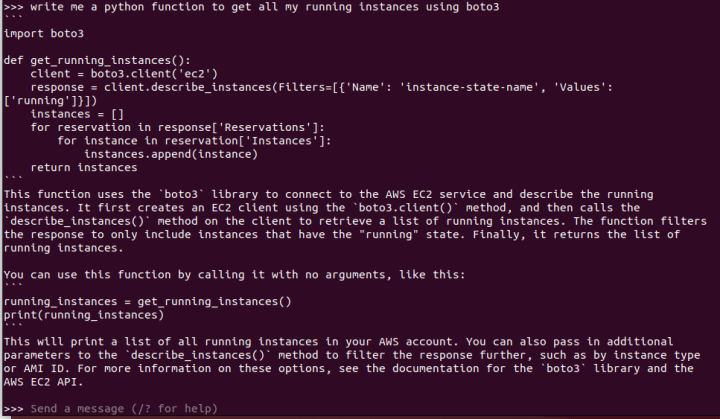
Now you can use the model through the console interface:
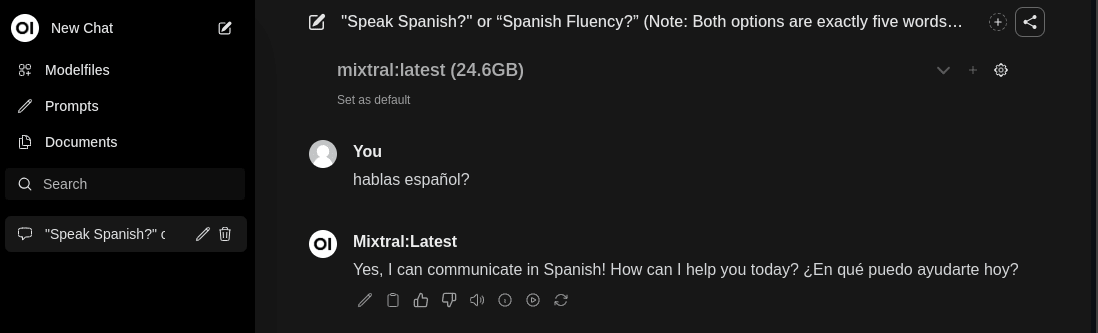
Installing a UI
This step is optional, but provides a UI via your web browser.
sudo snap install --beta open-webui
Access the web UI securely
To quickly access the UI without open ports in the Azure security group, you can create an SSH tunnel to your VM using the following command:
ssh -L 8080:localhost:8080 ubuntu@${IP_ADDR}
Go to http://localhost:8080 in your web browser on your local machine (the command above tunnels the traffic from your localhost to the instance on Azure).:
In case you want to make this service public, follow this documentation.
Verify GPU usage
sudo watch -n2 nvidia-smi
Check that the ollama process is using the GPU, you should see something like this:
+---------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |===========================================================================| | 0 N/A N/A 1063 C /snap/ollama/13/bin/ollama 4882MiB | +---------------------------------------------------------------------------+
Complementary and Alternative Solutions
- Charmed Kubeflow: Explore this solution for end-to-end MLOps (Machine Learning Operations), providing a streamlined platform to manage every stage of the machine learning lifecycle. It’s particularly well-suited for complex or large-scale AI deployments.
- Azure AI Studio: Provides ease of use for those seeking less customization.
Conclusion
Ubuntu’s open-source foundation and robust ecosystem make it a compelling choice for deploying open-source AI models. When combined with Azure’s GPU capabilities and Confidential Compute features, you gain a flexible, secure, and performant AI solution.