Les LLM les plus connus, qu'on trouve dans ChatGPT ou dans Gemini, deviennent de plus en plus performants, notamment en mathématiques. Pourtant, ce ne serait pas dû à leurs avancées technologiques. En fait, ces intelligences artificielles tricheraient avant même de répondre à des problèmes.
Qui n’a jamais rêvé d’automatiser n’importe quelle tâche web peu importe sa complexité, pour évidemment se la couler douce ?
C’est précisément ce que vous propose Skyvern, un outil qui allie intelligence artificielle et vision par ordinateur pour interagir avec les sites web comme vous le feriez vous-même.
Plus besoin de scripts qui pètent à tout bout de champs, de XPath qui changent tous les 4 matins et de parseurs de DOM capricieux puisque Skyvern est capable de comprendre visuellement ce qu’il y a sur une page web et ainsi générer un plan d’interaction en temps réel.
Cela signifie que Skyvern est capable d’agir sur des sites qu’il n’a jamais vus auparavant, le tout sans avoir besoin de code spécifique. Il analyse les éléments visuels de la page pour déterminer les actions nécessaires pour répondre à votre demande, ce qui en fait un outil immunisé contre les changements de design de sites, contrairement à votre bon vieux scrapper.
Grâce aux modèles de langage (LLM) qu’il embarque, il est capable de « raisonner » donc par exemple, de remplir un formulaire qui vous pose plein de questions, ou de comparer des produits.
Vous voulez voir Skyvern à l’œuvre ? Voici un petit aperçu en vidéo :
Sous le capot, Skyvern s’inspire des architectures d’agents autonomes comme BabyAGI et AutoGPT, avec une couche d’automatisation web en plus, basée sur des outils comme Playwright.
Et comme d’hab, vous pouvez installer la bête sur votre machine et commencer à automatiser tout votre boulot en quelques commandes.
Vous devrez donc avoir Python 3.11, puis installez poetry :
brew install poetry
Ensuite, clonez le dépôt git et aller dans le dossier :
Et voilà, vous pouvez maintenant envoyer des requêtes au serveur, mais ne vous inquiétez pas, y’a une interface graphique :). Pour la lancer :
./run_ui.sh
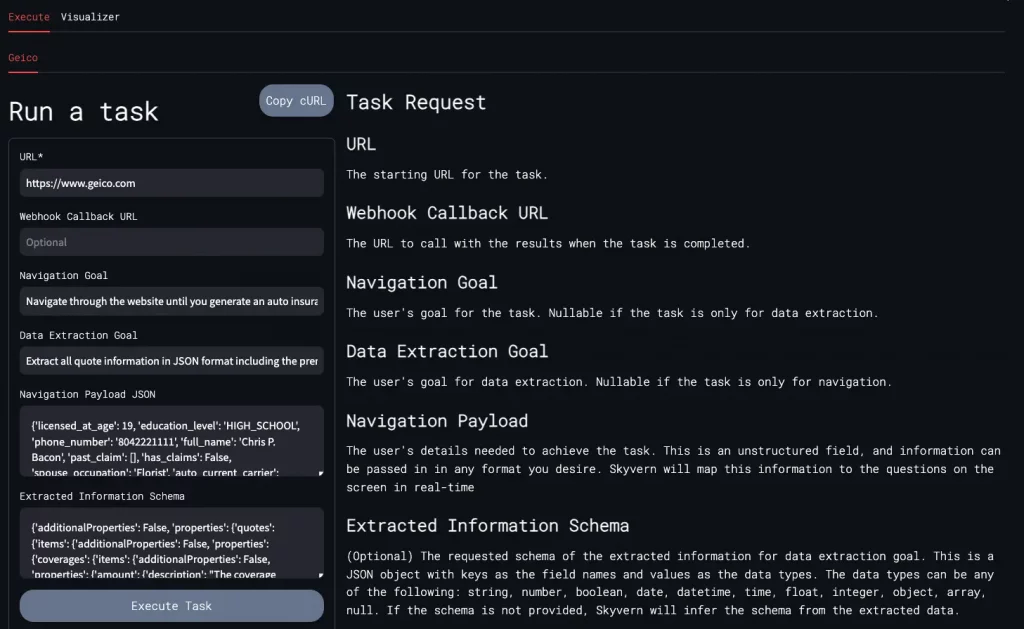
Ouvrez ensuite http://localhost:8501 dans votre navigateur pour y accéder. Vous verrez alors ce genre d’interface. A vous de remplir les champs qui vont bien pour créer votre première automatisation.
En commande cURL, ça ressemble à ça (pensez bien à mettre votre clé API locale dans la commande) :
curl -X POST -H 'Content-Type: application/json' -H 'x-api-key: {Votre clé API locale}' -d '{
"url": "https://www.geico.com",
"webhook_callback_url": "",
"navigation_goal": "Naviguer sur le site Web jusqu\'à ce que vous obteniez un devis d\'assurance automobile. Ne pas générer de devis d\'assurance habitation. Si cette page contient un devis d\'assurance automobile, considérez l\'objectif atteint",
"data_extraction_goal": "Extraire toutes les informations de devis au format JSON, y compris le montant de la prime et le délai du devis",
"navigation_payload": "{Vos données ici}",
"proxy_location": "NONE"
}' http://0.0.0.0:8000/api/v1/tasks
Vous voyez, on peut vraiment faire des trucs pointu. Et le petit plus, c’est qu’on peut voir toutes les interactions puisque Skyvern enregistre chaque action avec une capture d’écran correspondante pour vous permettre de débugger facilement vos workflows.
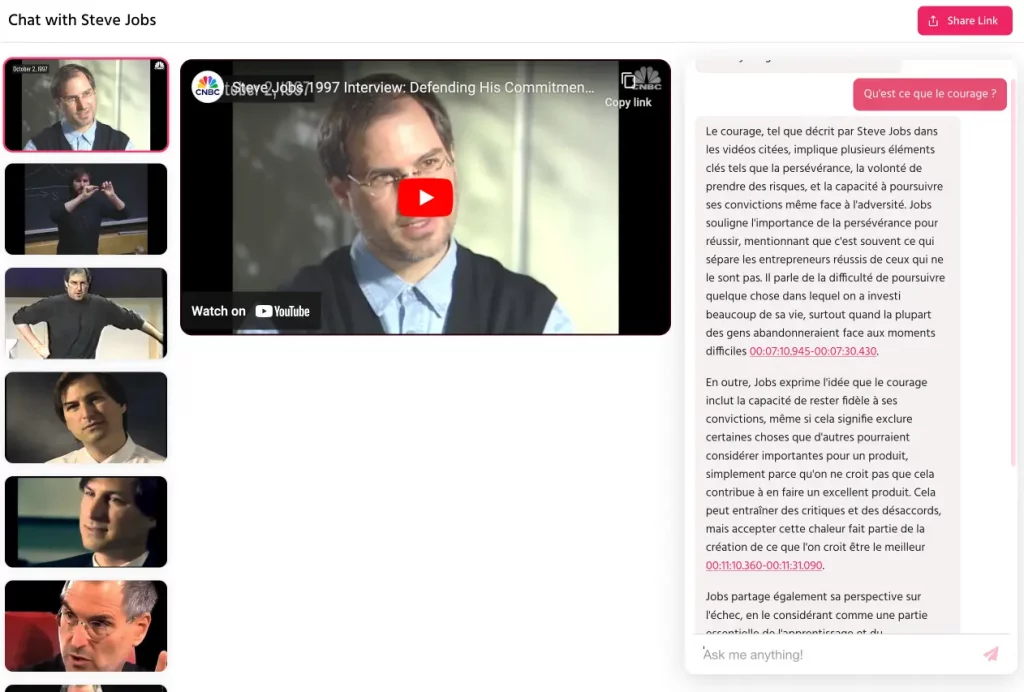
Grâce à la magie de l’intelligence artificielle, vous allez pouvoir discuter avec votre gourou préféré. Enfin, quand je dis « discuter », c’est un bien grand mot. Disons plutôt que vous allez pouvoir poser des questions à un modèle de langage entraîné sur une petite quantité d’interviews et discours de Steve Jobs himself.
Pour cela, le créateur de ce chatbot a utilisé un service nommé Jelli.io qui permet justement de chatter avec des vidéos et le résultat est plutôt cool, même si le chatbot n’incarne pas directement Steve Jobs (pour des questions éthiques j’imagine et pour n’énerver personne…)
Bref, de quoi vous inspirer et vous motiver sans forcement mater des heures et des heures d’interviews.
Sam Altman a pris la parole lors d'une conférence sur les progrès futurs de l'IA à l'Université de Stanford. L'occasion de parler du développement de GPT-5 et le patron d'OpenAI le promet : la prochaine évolution de ChatGPT sera grande.
Vous avez vu la dernière version d’Ollama ? Cette version 0.133 a l’air plutôt pas mal. Bon, je sais, je sais, ça faisait un bail que je n’avais pas parlé des mises à jour de cet outil génial pour faire tourner des modèles d’IA en local, mais là, impossible de passer à côté !
Déjà, on a le droit à des fonctionnalités expérimentales de parallélisme (je sais pas si c’est comme ça qu’on dit en français…) qui vont vous permettre d’optimiser grave vos applis d’IA. Il y a donc 2 nouvelles variables d’environnement qui débarquent : OLLAMA_NUM_PARALLEL et OLLAMA_MAX_LOADED_MODELS. Avec ça, vous allez pouvoir gérer plusieurs modèles et requêtes en même temps, comme des pros ! 😎
Par exemple, si vous avez un modèle pour compléter votre code avec une IA de 6 milliards de paramètres comme Llama 3, et en même temps vous demandez à Phi 3 Mini et ses 3,8 milliards de paramètres comment architecturer votre projet et bien maintenant, c’est possible ! Comme ça, plus besoin d’attendre que l’un ait fini pour lancer l’autre puisque tout ça va se lancer en parallèle.
Alors bien sûr, c’est encore expérimental car il n’y a pas encore de priorité, et on est limité par la mémoire dispo sur notre machine. D’ailleurs, il vaut mieux avoir 16 Go de RAM et un CPU 4 cœurs pour que ça fonctionne correctement.
Il y a aussi plein de nouveaux modèles d’IA compatibles avec Ollama maintenant. Des gros calibres comme Llama 3, le meilleur modèle open-source à ce jour, mais aussi des plus légers et spécialisés comme Phi 3 Mini, Moondream pour la vision par ordinateur sur des appareils à la marge, ou encore Dolphin Llama 3 qui répond sans censure. Et le premier modèle Qwen (c’est chinois) de plus de 100 milliards de paramètres, Qwen 110B, est également de la partie. Ça en fait des compagnons pour nous assister dans nos projets !
Ensuite, imaginons que vous vouliez tester le parallélisme. Vous devez simplement lancer votre serveur Ollama avec les fameuses variables d’environnement.
Voici comment procéder :
Définir les variables sur Mac :
Utilisez launchctl pour définir chaque variable. Par exemple, pour permettre à Ollama de gérer trois requêtes simultanément, tapez dans le terminal : launchctl setenv OLLAMA_NUM_PARALLEL 3
Pour définir le nombre maximal de modèles chargés simultanément à deux, utilisez : launchctl setenv OLLAMA_MAX_LOADED_MODELS 2
Après avoir défini les variables, redémarrez l’application Ollama.
Configurer les variables sur Linux :
Éditez le service systemd d’Ollama avec systemctl edit ollama.service, ce qui ouvrira un éditeur de texte.
Ajoutez les lignes suivantes sous la section [Service] : [Service] Environment="OLLAMA_NUM_PARALLEL=3" Environment="OLLAMA_MAX_LOADED_MODELS=2"
Sauvegardez et quittez l’éditeur. Rechargez systemd et redémarrez Ollama avec : systemctl daemon-reload systemctl restart ollama
Paramétrer les variables sur Windows :
Quittez l’application Ollama via la barre des tâches.
Accédez aux variables d’environnement système via le panneau de configuration et créez ou modifiez les variables pour votre compte utilisateur :
Pour OLLAMA_NUM_PARALLEL, ajoutez ou modifiez la variable à 3.
Pour OLLAMA_MAX_LOADED_MODELS, ajustez la variable à 2.
Appliquez les changements et redémarrez Ollama à partir d’une nouvelle fenêtre de terminal.
Là, ça veut dire que vous pourrez envoyer 3 requêtes en parallèle sur le même modèle, et charger jusqu’à 2 modèles différents si votre RAM de 16 Go minimum le permet.
Bon, et une fois que c’est lancé, vous pourrez envoyer des requêtes à tour de bras. Un coup à Llama 3 pour qu’il vous aide à générer un résumé de texte hyper optimisé, un autre à Phi 3 Mini pour résumer un article scientifique, tout ça pendant que Moondream analyse une image pour de la détection d’objets.
Allez, je vous laisse tranquille, faut que j’aille optimiser mes scripts maintenant.
Grâce à l'intelligence artificielle, de plus en plus de services sont capables de reconnaître le contenu d'une image. Pour identifier un insecte, une plante ou un paysage, il ne faut que quelques secondes.
Utilisez-vous un moteur de recherche traditionnel quand vous cherchez une information en ligne ou votre premier réflexe est-il devenu un réseau social, une plateforme vidéo ou un chatbot boosté à l'IA ? C'est la question de notre sondage hebdomadaire.
La SNCF mène des expérimentations sur la vidéosurveillance algorithmique (VSA) dans trois gares, à Paris et Marseille. Les tests ont déclenché une action de La Quadrature du Net devant la Cnil, avec l'espoir d'y mettre fin.
Google est encore très prudent concernant l'utilisation de l'intelligence artificielle générative dans ses produits. Mais cette prudence pourrait-elle finalement causer sa chute ? OpenAI, l'éditeur de ChatGPT, pourrait bientôt lancer un moteur de recherche basé sur sa technologie ChatGPT, qui pourrait concurrencer directement Google.
ChatRTX, le chatbot expérimental de Nvidia qui fonctionne en local, se complète avec l'arrivée des modèles Gemma de Google, versions ouvertes de Gemini. De quoi avoir des alternatives respectueuses de la vie privée à ChatGPT, Copilot, Gemini et autres, le tout sur un PC Windows.
Déjà accusé d'utiliser des scripts pour exécuter des tâches sur Internet, le rabbit r1 est de nouveau dans la tourmente après la découverte d'un journaliste d'Android Authority. Le « système d'exploitation » du r1 est une application Android préinstallée sur un terminal AOSP, la version open source du système de Google.
La puissance de calculs des derniers processeurs et cartes graphiques vendues dans le commerce offre de nouvelles opportunités pour les cybercriminels. Les internautes doivent réfléchir à de nouveaux mots de passe face à la hausse de cette menace.
En plus des URL et des recherches, la barre d'adresse de Chrome permet désormais de poser des questions à Gemini, le chatbot de Google. L'entreprise déploie aussi ses extensions en France.
Apparu mystérieusement sur un site de comparaison des grands modèles de langage, le modèle gpt2-chatbot intrigue la communauté de l'intelligence artificielle (IA). Supposément capable de résoudre des problèmes inabordables pour GPT-4, il pourrait être un prototype d'un futur modèle OpenAI. Sam Altman, le patron de l'entreprise, ne cache pas son amusement.