Skyvern – Plus besoin de vous prendre la tête pour automatiser une tâche web (scraping, saisie de formulaire…etc)

Qui n’a jamais rêvé d’automatiser n’importe quelle tâche web peu importe sa complexité, pour évidemment se la couler douce ?
C’est précisément ce que vous propose Skyvern, un outil qui allie intelligence artificielle et vision par ordinateur pour interagir avec les sites web comme vous le feriez vous-même.
Plus besoin de scripts qui pètent à tout bout de champs, de XPath qui changent tous les 4 matins et de parseurs de DOM capricieux puisque Skyvern est capable de comprendre visuellement ce qu’il y a sur une page web et ainsi générer un plan d’interaction en temps réel.
Cela signifie que Skyvern est capable d’agir sur des sites qu’il n’a jamais vus auparavant, le tout sans avoir besoin de code spécifique. Il analyse les éléments visuels de la page pour déterminer les actions nécessaires pour répondre à votre demande, ce qui en fait un outil immunisé contre les changements de design de sites, contrairement à votre bon vieux scrapper.
Grâce aux modèles de langage (LLM) qu’il embarque, il est capable de « raisonner » donc par exemple, de remplir un formulaire qui vous pose plein de questions, ou de comparer des produits.
Vous voulez voir Skyvern à l’œuvre ? Voici un petit aperçu en vidéo :
Sous le capot, Skyvern s’inspire des architectures d’agents autonomes comme BabyAGI et AutoGPT, avec une couche d’automatisation web en plus, basée sur des outils comme Playwright.

Et comme d’hab, vous pouvez installer la bête sur votre machine et commencer à automatiser tout votre boulot en quelques commandes.
Vous devrez donc avoir Python 3.11, puis installez poetry :
brew install poetryEnsuite, clonez le dépôt git et aller dans le dossier :
git clone https://github.com/Skyvern-AI/skyvern.gitcd skyvern
Puis lancez le script d’install :
./setup.sh
Une fois que c’est fini, démarrez le serveur :
./run_skyvern.shEt voilà, vous pouvez maintenant envoyer des requêtes au serveur, mais ne vous inquiétez pas, y’a une interface graphique :). Pour la lancer :
./run_ui.shOuvrez ensuite http://localhost:8501 dans votre navigateur pour y accéder. Vous verrez alors ce genre d’interface. A vous de remplir les champs qui vont bien pour créer votre première automatisation.
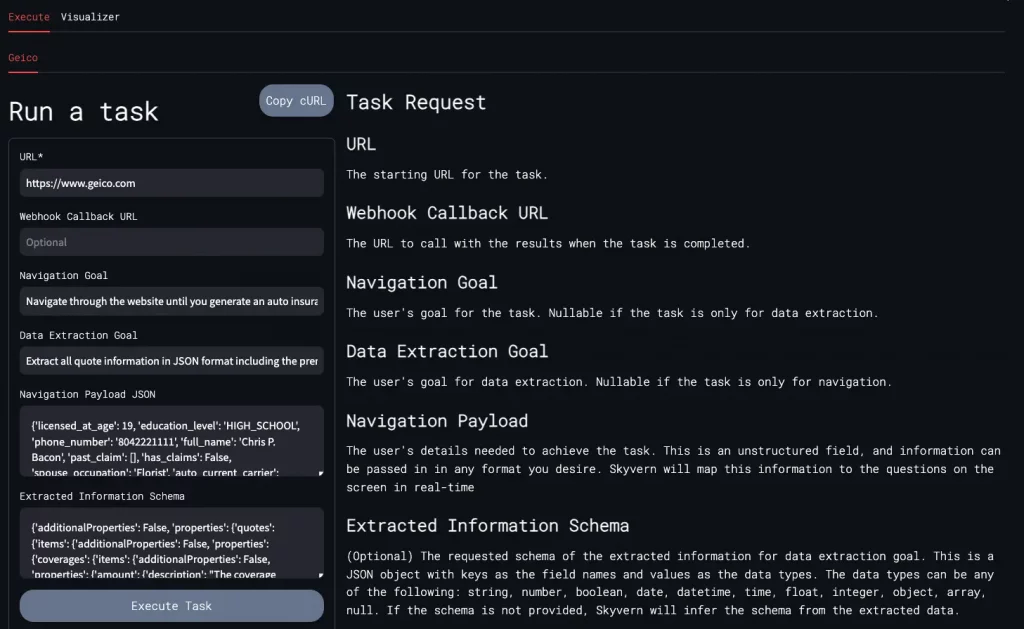
En commande cURL, ça ressemble à ça (pensez bien à mettre votre clé API locale dans la commande) :
curl -X POST -H 'Content-Type: application/json' -H 'x-api-key: {Votre clé API locale}' -d '{
"url": "https://www.geico.com",
"webhook_callback_url": "",
"navigation_goal": "Naviguer sur le site Web jusqu\'à ce que vous obteniez un devis d\'assurance automobile. Ne pas générer de devis d\'assurance habitation. Si cette page contient un devis d\'assurance automobile, considérez l\'objectif atteint",
"data_extraction_goal": "Extraire toutes les informations de devis au format JSON, y compris le montant de la prime et le délai du devis",
"navigation_payload": "{Vos données ici}",
"proxy_location": "NONE"
}' http://0.0.0.0:8000/api/v1/tasks
Vous voyez, on peut vraiment faire des trucs pointu. Et le petit plus, c’est qu’on peut voir toutes les interactions puisque Skyvern enregistre chaque action avec une capture d’écran correspondante pour vous permettre de débugger facilement vos workflows.
Bref, pour en savoir plus, c’est sur le Github. Et sur leur site officiel.