Dans quelques jours, Microsoft va participer à l'Open Source Summit 2024, mais pourquoi ? Bien que cela puisse surprendre, sachez qu'au final, c'est plutôt évident et cohérent.
L'Open Source Summit North America est un événement organisé par la Fondation Linux et l'édition 2024 se déroulera du 16 au 18 avril prochain, à Seattle, aux États-Unis. Microsoft va participer à cet événement mondial, tout en étant un sponsor "Platinum", au même titre que Docker et Red Hat. D'ailleurs, au passage, AWS et Google sont des sponsors "Diamond" de cet événement.
Bien que Microsoft soit toujours associé à une étiquette d'"éditeur de solutions propriétaires", notamment parce que son système d'exploitation Windows est un OS propriétaire, la position de l'entreprise américaine a évoluée depuis environ 10 ans. Depuis 2014 et l'arrivée en Satya Nadella en tant que Directeur général, pour être plus précis. Si Microsoft a commencé à adopter l'open source dans ses activités principales et à participer à différents projets, c'est grâce à lui.
Microsoft est impliqué dans de nombreux projets Open Source
À l'occasion de sa participation à l'Open Source Summit, Microsoft discutera de ses contributions à la communauté open source. Aujourd'hui, Microsoft se félicite de participer au développement de Linux, à des langages de programmation tels que PHP, Python et Node.js, mais aussi à PostgreSQL ou encore à ses propres solutions open source comme .NET Core, Visual Studio Code et TypeScript.
"En outre, l'open source est au cœur de notre stratégie produit et constitue un élément fondamental de notre culture. Aujourd'hui, plus de 60 000 employés de Microsoft utilisent GitHub et nous gérons plus de 14 000 dépôts publics couvrant tout, des meilleures pratiques et de l'ensemble de nos systèmes de documentation aux projets innovants tels que PowerTools et PowerShell.", peut-on lire sur le site de Microsoft.
La firme de Redmond partagera également ses meilleures pratiques pour l'utilisation des technologies open source et les tendances émergentes dans ce domaine. D'ailleurs, en interne, Microsoft a eu équipe en charge de veiller sur la bonne utilisation des logiciels libres : "Le Microsoft Open Source Programs Office (OSPO) veille à ce que nous utilisions correctement les logiciels libres, à ce que nous fournissions des solutions sécurisées à nos clients et à ce que nous participions de manière authentique aux communautés de logiciels libres."
Pour Microsoft, l'intérêt est aussi d'assurer une compatibilité et une prise en charge avec ses solutions telles que Microsoft Intune ou encore le Cloud Azure au sein duquel les organisations peuvent exécuter des machines virtuelles sous Linux. "Microsoft prend en charge les principales distributions Linux et collabore étroitement avec Red Hat, SUSE, Canonical et l'ensemble de la communauté Linux.", précise Microsoft.
Des chercheurs en sécurité ont découvert une vulnérabilité qu'ils considèrent comme le "premier exploit natif Spectre v2" qui affecte les systèmes Linux fonctionnant avec de nombreux processeurs Intel récents ! En exploitant cette vulnérabilité, un attaquant pourrait lire des données sensibles dans la mémoire. Voici ce qu'il faut savoir !
La vulnérabilité Spectre et l'exécution spéculative
Avant tout, commençons par quelques mots sur la vulnérabilité Spectre en elle-même, ainsi que sur l'exécution spéculative.
Découverte au sein des processeurs Intel et AMD il y a plusieurs années, Spectre et sa copine Meltdown sont parmi les vulnérabilités les plus populaires. Ces termes font aussi référence à des techniques d'attaques visant à exploiter les failles de sécurité en question. Spectre affecte de nombreux processeurs dotés de l'exécution spéculative et corriger cette faille de sécurité matérielle n'est pas simple, car cela affecte, de façon importante, les performances du CPU.
L'exécution spéculative vise à améliorer les performances de la machine grâce au processeur qui va chercher à deviner la prochaine instruction à exécuter. La puissance des processeurs modernes permet de prédire plusieurs chemins qu'un programme peut emprunter et les exécuter simultanément. Cela ne fonctionne pas toujours, mais quand c'est le cas, cela booste les performances. Malgré tout, cela représente un risque, car le cache du CPU peut contenir des traces avec des données sensibles (mots de passe, informations personnelles, code logiciel, etc.), et celles-ci sont potentiellement accessibles par un attaquant lorsqu'une vulnérabilité est découverte.
Il y a deux méthodes d'attaques nommées Branch Target Injection (BTI) et Branch History Injection (BHI).
L'exploitation de Spectre V2 sur Linux
Récemment, une équipe de chercheurs du groupe VUSec de VU Amsterdam a fait la découverte de Spectre V2, une nouvelle variante de l'attaque Spectre originale, associée à la référence CVE-2024-2201. Vous pouvez retrouver leur rapport sur cette page.
Le CERT/CC a mis en ligne un bulletin de sécurité à ce sujet, dans lequel nous pouvons lire ceci : "Un attaquant non authentifié peut exploiter cette vulnérabilité pour faire fuir la mémoire privilégiée du CPU en sautant spéculativement vers un gadget choisi.", c'est-à-dire un chemin de code.
Dans le cas présent, le nouvel exploit, appelé Native Branch History Injection (en référence à l'attaque BHI), peut être utilisé pour faire fuir la mémoire arbitraire du noyau Linux à une vitesse de 3,5 kB/sec en contournant les mesures d'atténuation existantes de Spectre v2/BHI.
Pour se protéger, le CERT/CC recommande d'appliquer les dernières mises à jour publiées par les éditeurs et précise ceci : "Les recherches actuelles montrent que les techniques d'atténuation existantes, à savoir la désactivation de l'eBPF privilégié et l'activation de l'IBT, sont insuffisantes pour empêcher l'exploitation de BHI contre le noyau/l'hyperviseur."
De son côté, Intel a mis à jour ses recommandations d'atténuation pour Spectre v2 et propose désormais de désactiver la fonctionnalité "Extended Berkeley Packet Filter" non privilégiée (eBPF), d'activer les fonctionnalités "Enhanced Indirect Branch Restricted Speculation" (eIBRS) et "Supervisor Mode Execution Protection" (SMEP).
Voici une vidéo de démonstration d'exploitation de cette vulnérabilité :
Qui est affecté par la vulnérabilité Spectre V2 ?
Le noyau Linux étant affecté, cette vulnérabilité va forcément impacter de nombreuses distributions. L'équipe de développement du noyau Linux mène actuellement des travaux pour trouver une solution. Mais, en fait, l'impact dépend aussi du matériel, car la vulnérabilité Spectre V2 affecte les processeurs Intel, et non les processeurs AMD.
D'un point de vue du système d'exploitation, si nous visitons le site de Debian, nous pouvons voir que les différentes versions sont vulnérables (Sid, Bookworm, Bullseye, Buster, etc.). SUSE Linux est également impactée, comme le mentionne cette page. Du côté de Red Hat Linux Enterprise, on affirme que l'eBPF non privilégié est désactivé par défaut, de sorte que le problème n'est pas exploitable dans les configurations standard.
Une liste publiée sur la page du CERT/CC permet d'accéder facilement aux liens des différents éditeurs et d'effectuer le suivi dans les prochains jours.
Finalement, cette nouvelle découverte souligne la difficulté de trouver un équilibre entre l'optimisation des performances et la sécurité, puisque ceci pourrait contraindre les utilisateurs à se passer de certaines fonctionnalités relatives au CPU.
Dans cet article, nous allons revenir sur la porte dérobée présente dans la bibliothèque XZ Utils afin d'évoquer les distributions Linux affectées, ainsi qu'un outil permettant de vérifier si votre serveur est affecté ou non !
Pour rappel, la bibliothèque de compression de données XZ Utils, correspondante au paquet "liblzma", est victime d'une compromission de la chaîne d'approvisionnement (supply chain attack) : les deux dernières versions (5.6.0 et 5.6.1) contiennent du code malveillant qui permet de déployer une porte dérobée sur le système. Cette backdoor offre la possibilité de se connecter en SSH sur la machine et d'exécuter du code malveillant sans être authentifié.
Cette vulnérabilité est associée à la référence CVE-2024-3094 et elle est considérée comme critique (score CVSS v3.1 de 10 sur 10).
Tout d'abord, sachez que les versions vulnérables de XZ Utils sont utilisées par certaines distributions Linux en cours de développement, dont voici la liste :
Fedora Rawhide
Fedora 41
Debian Sid (les versions testing, unstable et expérimentale de Debian)
openSUSE Tumbleweed
openSUSE MicroOS
Par ailleurs, si vous utilisez Kali Linux, votre machine peut être affectée : "Si vous avez mis à jour votre installation Kali le 26 mars ou après, mais avant le 29 mars, il est crucial d'appliquer les dernières mises à jour aujourd'hui pour résoudre ce problème.", peut-on lire sur cette page du site de Kali Linux.
Désormais, les mainteneurs de ces différentes distributions ont fait le nécessaire pour revenir sur une version non vulnérable. Cependant, c'est-à-vous de faire la manipulation pour revenir en arrière si votre machine est affectée.
Pour vérifier si votre machine est affectée ou non, vous pouvez exécuter le script Bash "CVE-2024-3094 Checker" disponible sur GitHub. Ce script communautaire fonctionne sur les différentes distributions et va regarder qu'elle est la version de XZ Utils installée sur votre machine, et vous indiquer, si oui ou non, vous êtes vulnérable.
Par exemple, sur une machine Debian, la commande suivante est utilisée pour effectuer la vérification :
dpkg -l | grep "xz-utils"
Pour rappel, vous ne devez pas utiliser les versions 5.6.0 et 5.6.1 de XZ Utils, car elles sont compromises. D'ailleurs, si vous utilisez une distribution où le gestionnaire de paquets Apt est utilisé (Debian, par exemple), le script vous proposera de revenir sur la version stable non compromise la plus récente, à savoir la 5.4.6. Enfin, il est également recommandé de lire le bulletin de sécurité publié sur le site de la distribution que vous utilisez.
Grosse alerte de sécurité : la bibliothèque "liblzma" utilisée par de nombreuses distributions Linux est victime d'une compromission de la chaîne d'approvisionnement : les dernières versions contiennent du code malveillant qui permet de déployer une porte dérobée sur le système. Faisons le point sur cette menace.
La bibliothèque liblzma appelée aussi XZ Utils est présente dans de nombreuses distributions Linux, notamment Arch Linux, Fedora, Debian, OpenSUSE, Alpine Linux, etc... Il s'agit d'une bibliothèque de compression de données susceptible d'être utilisées par d'autres applications.
Il s'avère que deux versions de la bibliothèque liblzma sont impactées par une attaque de type supply chain : 5.6.0 ou 5.6.1. La version 5.6.0 date de fin février tandis que la version 5.6.1 a été publiée le 9 mars 2024. Ces deux versions du paquet XZ contiennent du code malveillant qui a été très bien dissimulé par les auteurs de cette attaque, par l'intermédiaire d'un fichier m4 avec du code obfusqué. Il est visible uniquement lorsque le paquet est téléchargé en intégralité, donc il est invisible sur Git, par exemple.
Andres Freund, ingénieur logiciel chez Microsoft, a fait la découverte de ce problème de sécurité en menant des investigations sur une machine Debian Sid, après avoir constaté que les connexions SSH étaient anormalement longues.
Si une version compromise du paquet XZ est installée sur une machine, alors une porte dérobée est également déployée. Celle-ci offre un accès distant à l'attaquant qui pourrait se connecter à votre machine par l'intermédiaire d'une connexion SSH, sans avoir besoin de connaître vos identifiants (car il y a un lien entre systemd et liblzma).
Sachez que ceci est considéré comme une vulnérabilité et que la référence CVE pour cette faille de sécurité critique est la suivante : CVE-2024-3094. Sans surprise, un score CVSS v3.1 de 10 sur 10 a été associé à cette vulnérabilité.
Quels sont les systèmes affectés ?
Même si plusieurs distributions telles que Debian, Fedora ou encore Arch Linux sont concernées, ceci n'affecte pas toutes les versions. En effet, ceci concerne avant tout les versions en cours de développement, dont Debian Sid qui est la future version stable de Debian.
Pour Fedora, sachez que Fedora Rawhide et Fedora 41 sont affectées par ce problème de sécurité. Au sein du bulletin de sécurité de Red Hat, nous pouvons également lire ceci : "Aucune version de Red Hat Enterprise Linux (RHEL) n'est concernée.", ce qui n'est pas surprenant.
Potentiellement, tout autre système avec le paquet XZ en version 5.6.0 ou 5.6.1 est également affecté, donc vérifiez vos machines. Dans ce cas, il convient d'effectuer un downgrade vers la version 5.4.6.
Cette commande doit permettre d'obtenir la version :
dpkg -l | grep "xz-utils"
Pour approfondir le sujet, vous pouvez lire cet article intéressant qui donne des détails techniques supplémentaires, ainsi que l'origine de cette compromission : un nouveau développeur qui est venu épauler le créateur de la bibliothèque XZ Utils.
Dans ce tutoriel, nous allons avoir comment configurer l'authentification LDAP de GLPI pour pouvoir se connecter à l'application GLPI à partir des comptes utilisateurs présents dans un annuaire Active Directory. Ainsi, un utilisateur pourra accéder à GLPI à l'aide de son nom d'utilisateur et son mot de passe habituel (puisque ce seront les informations de son compte dans l'Active Directory).
GLPI propose nativement un modèle d'authentification LDAP, ce qui lui permet de s'appuyer sur un annuaire de comptes externe, comme l'Active Directory de Microsoft. Il faut savoir que les comptes utilisateurs de l'Active Directory seront importés dans la base de données de GLPI, grâce à un processus de synchronisation. Lorsqu'un utilisateur Active Directory se connecte pour la première fois, son compte est créé dans GLPI. Avant cela, il n'est pas visible, sauf si vous décidez d'effectuer un "import en masse" des comptes AD dans GLPI.
Avant de passer à la configuration, voici quelques informations sur l'environnement utilisé.
Pour cette démonstration, le domaine Active Directory "it-connect.local" sera utilisé et le contrôleur de domaine SRV-ADDS-02 sera utilisé. Ce serveur dispose de l'adresse IP "10.10.100.11" et la connexion sera effectuée en LDAP, sur le port par défaut (389).
- Le compte utilisateur qui sera utilisé comme "connecteur" pour permettre à GLPI de se connecter à l'Active Directory se nomme "Sync_GLPI". Il est stocké dans l'unité d'organisation "Connecteurs" de l'annuaire (voir image ci-dessous). Il s'agit d'un compte utilisateur standard, sans aucun droit particulier sur l'annuaire Active Directory. Faites-moi plaisir : n'utilisez pas de compte Administrateur.
- Tous les utilisateurs qui doivent pouvoir se connecter à GLPI à l'aide de leur compte Active Directory sont stockés dans l'unité d'organisation "Personnel" visible ci-dessous. Elle correspond à ce que l'on appelle la "Base DN" vis-à-vis du connecteur LDAP de GLPI. Les autres utilisateurs ne pourront pas se connecter. En fait, ce n'est pas utile de mettre la racine du domaine comme base DN : essayez de restreindre autant que possible pour limiter la découverte de l'annuaire Active Directory au strict nécessaire.
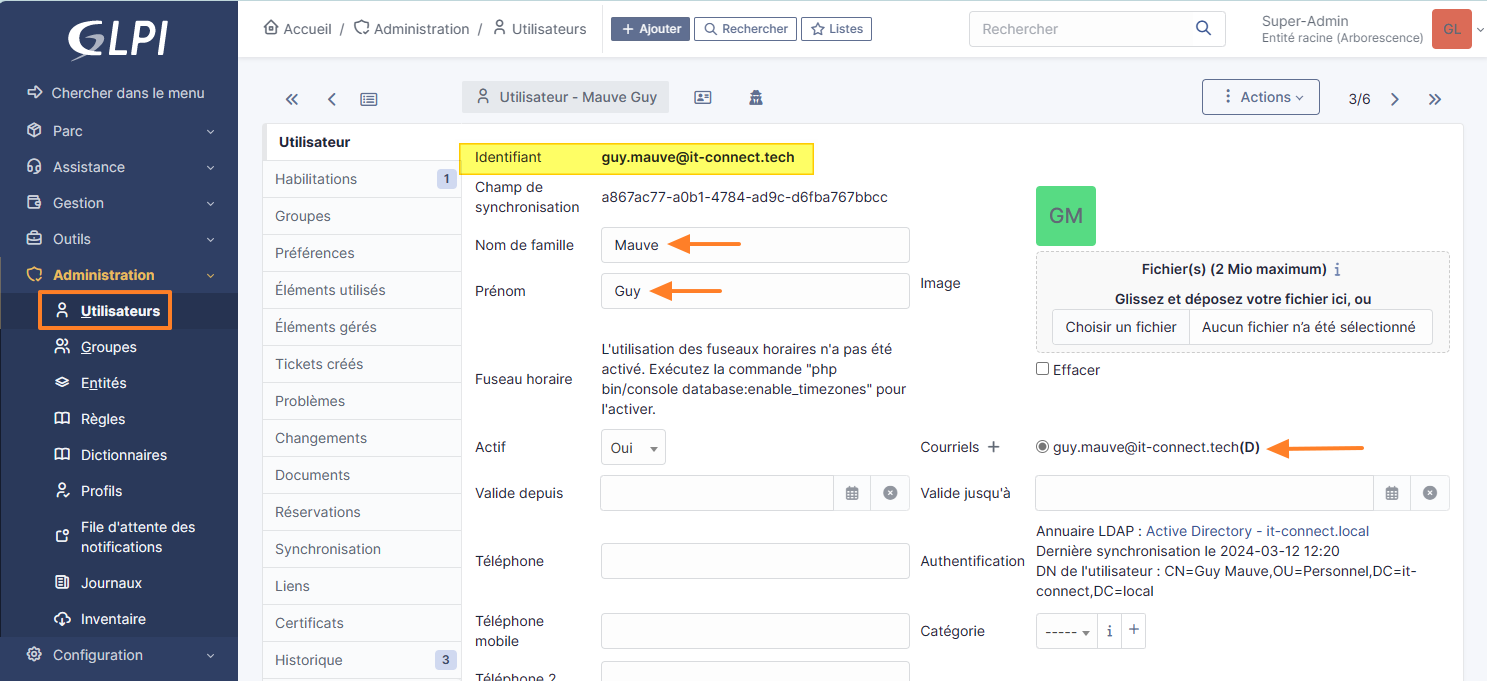
- Les utilisateurs de l'Active Directory pourront se connecter à GLPI à l'aide de leur identifiant correspondant à l'attribut "UserPrincipalName" (mis en évidence, en jaune, sur l'image ci-dessous). Cet identifiant, sous la forme "identifiant + nom de domaine", leur permettra se connecter à GLPI avec un identifiant qui correspond à leur e-mail. L'alternative consisterait à utiliser l'attribut "SamAccountName" (soit l'identifiant sous la forme "DOMAINE\identifiant").
Voilà, maintenant, nous allons pouvoir dérouler la configuration !
II. Installer l'extension LDAP de PHP
L'extension LDAP de PHP doit être installée sur votre serveur pour que GLPI soit capable de communiquer avec votre serveur contrôleur de domaine Active Directory (ou tout autre annuaire LDAP).
Connectez-vous à votre serveur GLPI et exécutez les deux commandes suivantes pour mettre à jour le cache des paquets et procéder à l'installation de l'extension.
sudo apt-get update
sudo apt-get install php-ldap
Cette extension sera installée et activée dans la foulée. Vous n'avez pas besoin de relancer le serveur.
III. Ajouter un annuaire LDAP dans GLPI
Désormais, nous allons ajouter notre annuaire Active Directory à GLPI. Connectez-vous à GLPI avec un compte administrateur, puis dans le menu "Configuration", cliquez sur "Authentification".
Au centre de l'écran, cliquez sur "Annuaire LDAP".
Puis, cliquez sur le bouton "Ajouter".
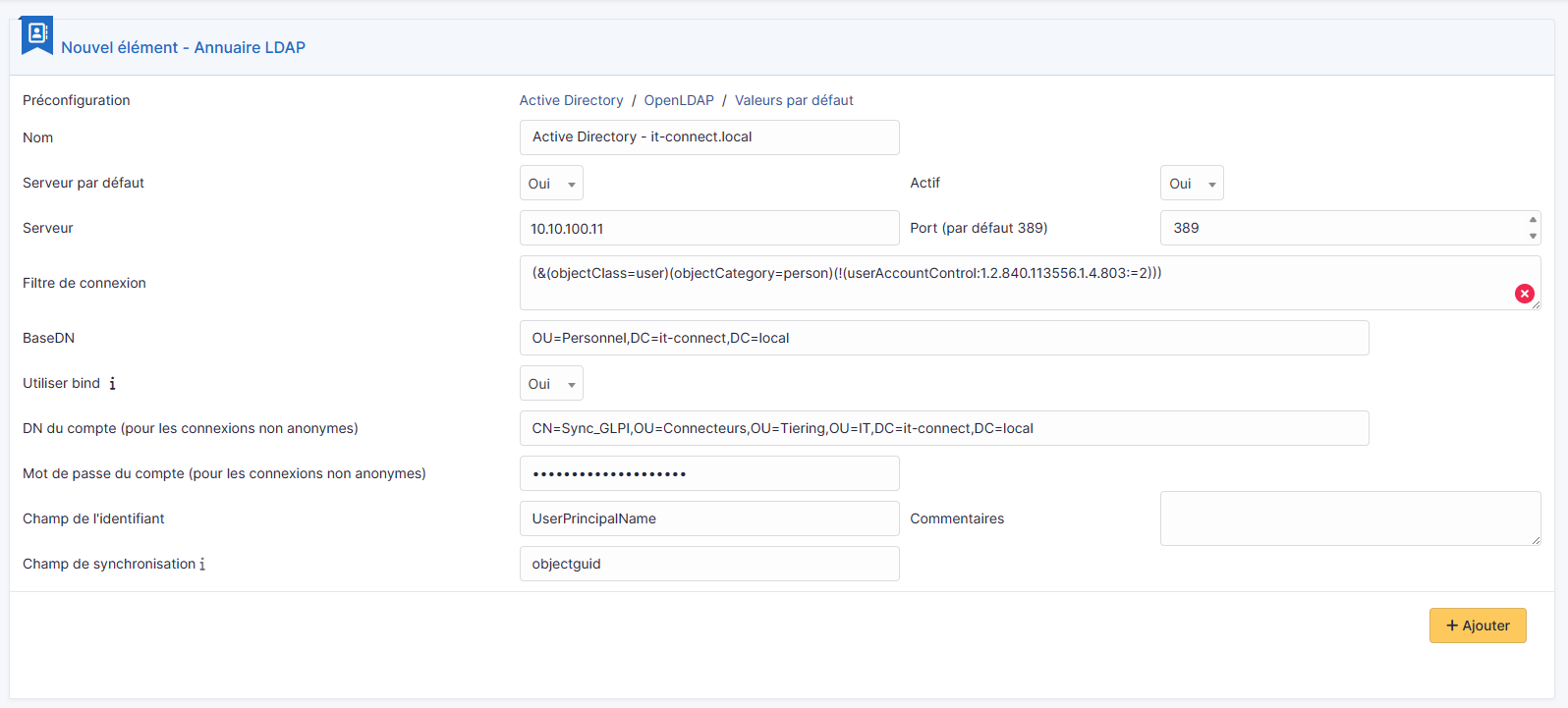
Un formulaire s'affiche à l'écran. Comment le renseigner ? À quoi correspondent tous ces champs ? C'est que nous allons voir ensemble.
Nom : le nom de cet annuaire LDAP, vous pouvez utiliser un nom convivial, ce n'est pas obligatoirement le nom du domaine, ni le nom du serveur.
Serveur par défaut : faut-il s'appuyer sur ce serveur par défaut pour l'authentification LDAP ? Il ne peut y avoir qu'un seul serveur LDAP défini par défaut.
Actif : nous allons indiquer "Oui", sinon ce sera déclaré, mais non utilisé.
Serveur : adresse IP du contrôleur de domaine à interroger. Avec le nom DNS, cela ne semble pas fonctionner (malheureusement).
Port : 389, qui est le port par défaut du protocole LDAP. Si vous utilisez TLS, il faudra le préciser à postériori, dans l'onglet "Informations avancées", du nouveau serveur LDAP.
Filtre de connexion : requête LDAP pour rechercher les objets dans l'annuaire Active Directory. Généralement, nous faisons en sorte de récupérer les objets utilisateurs ("objectClass=user") en prenant uniquement les utilisateurs actifs (via un filtre sur l'attribut UserAccountControl).
BaseDN : où faut-il se positionner dans l'annuaire pour rechercher les utilisateurs ? Ce n'est pas nécessaire la racine du domaine, tout dépend comment est organisé votre annuaire et où se situent les utilisateurs qui doivent pouvoir se connecter. Il faut indiquer le DistinguishedName de l'OU.
Utiliser bind : à positionner sur "Oui" pour du LDAP classique (sans TLS)
DN du compte : le nom du compte à utiliser pour se connecter à l'Active Directory. En principe, vous ne pouvez pas utiliser de connexion anonyme ! Ici, il ne faut pas indiquer uniquement le nom du compte, mais la valeur de son attribut DistinguishedName.
Mot de passe du compte : le mot de passe du compte renseigné ci-dessus
Champ de l'identifiant : dans l'Active Directory, quel attribut doit être utilisé comme identifiant de connexion pour le futur compte GLPI ? Généralement, UserPrincipalName ou SamAccountName, selon vos besoins.
Champ de synchronisation : GLPI a besoin d'un champ sur lequel s'appuyer pour synchroniser les objets. Ici, nous allons utiliser l'objectGuid de façon à avoir une valeur unique pour chaque utilisateur. Ainsi, si un utilisateur est modifié dans l'Active Directory, GLPI pourra se repérer grâce à cet attribut qui lui n'évoluera pas (sauf si le compte est supprimé puis recréé dans l'AD).
Ci-dessous, la configuration utilisée pour cette démonstration et qui correspond à la "configuration cible" évoquée précédemment.
Nom : Active Directory - it-connect.local
Serveur par défaut : Oui
Actif : Oui
Serveur : 10.10.100.11
Port : 389
Filtre de connexion : (&(objectClass=user)(objectCategory=person)(!(userAccountControl:1.2.840.113556.1.4.803:=2)))
BaseDN : OU=Personnel,DC=it-connect,DC=local
Utiliser bind : Oui
DN du compte : CN=Sync_GLPI,OU=Connecteurs,OU=Tiering,OU=IT,DC=it-connect,DC=local
Mot de passe du compte : Mot de passe du compte "Sync_GLPI"
Champ de l'identifiant : userprincipalname
Champ de synchronisation : objectguid
Quand votre configuration est prête, cliquez sur "Ajouter".
Dans la foulée, GLPI va effectuer un test de connexion LDAP et vous indiquer s'il est parvenu, ou non, à se connecter à votre annuaire. Si ce n'est pas le cas (comme moi, la première fois), cliquez sur le nom de votre annuaire, vérifiez la configuration, puis retournez dans "Tester" sur la gauche afin de lancer un nouveau test. Pour ma part, le problème venait du champ "Serveur" : j'avais mis le nom DNS du serveur à la place de l'adresse IP, mais cela ne fonctionnait pas. Pourtant, mon serveur GLPI parvient bien à résoudre le nom DNS.
Par ailleurs, vous pouvez explorer les différents onglets : Utilisateurs, Groupes, Réplicats, etc... Pour affiner la configuration. L'onglet "Utilisateurs" est intéressant pour configurer le mappage entre les champs d'une fiche utilisateur dans GLPI et les attributs d'un compte dans l'Active Directory. Quant à l'onglet "Réplicats", vous pouvez l'utiliser pour déclarer un ou plusieurs contrôleurs de domaine "de secours" à contacter si le serveur principal n'est plus joignable.
IV. Tester la connexion Active Directory
Si GLPI valide la connexion à votre annuaire Active Directory, vous pouvez tenter de vous authentifier à l'application avec un compte utilisateur. Pour ma part, c'est l'utilisateur Guy Mauve qui va servir de cobaye. Son login GLPI sera donc "guy.mauve@it-connect.tech" puisque je m'appuie sur l'attribut UserPrincipalName. Pour le mot de passe, je dois indiquer celui de son compte Active Directory.
Remarque : la source d'authentification doit être l'Active Directory.
Voilà, l'authentification fonctionne ! L'utilisateur a pu se connecter avec son compte Active Directory et il hérite du rôle "Self-service".
Dans le même temps, à partir du compte admin de GLPI, je peux remarquer la présence d'un nouveau compte utilisateur dont l'identifiant est "guy.mauve@it-connect.tech" ! GLPI a également récupéré le nom, le prénom et l'adresse e-mail à partir de différents attributs de l'objet LDAP.
V. Forcer une synchronisation Active Directory
A partir de GLPI, vous pouvez forcer une synchronisation LDAP de façon à mettre à jour les comptes dans GLPI "liés" à des comptes Active Directory, mais aussi pour importer en masse tous les comptes des utilisateurs Active Directory. Ceci vous évite d'attendre la première connexion et vous permet de préparer le compte : attribution du bon rôle, etc.
Cliquez sur "Administration" dans le menu, puis "Utilisateurs". Ici, vous avez accès au bouton "Liaison annuaire LDAP".
Vous avez ensuite le choix entre deux actions différentes, selon vos besoins.
Si vous cliquez sur "Importation de nouveaux utilisateurs", vous pourrez importer en masse les comptes dans l'Active Directory. Il vous suffit de lancer une recherche, de sélectionner les comptes à importer et de lancer l'import grâce au bouton "Actions".
Remarque : vous pouvez aussi importer des groupes Active Directory. Pour cela, suivez la même procédure, mais en allant dans "Groupes" sous "Administration".
VI. Conclusion
En suivant ce tutoriel, vous devriez être en mesure d'importer les comptes utilisateurs d'un annuaire Active Directory dans GLPI, pour faciliter la connexion de vos utilisateurs. Sachez que si un utilisateur change son mot de passe dans l'Active Directory, ce n'est pas un problème : GLPI vérifie les informations lors de la connexion.
Un chercheur en sécurité a identifié un nouveau logiciel malveillant destructeur de données, nommé AcidPour, et qui cible les équipements réseau ainsi que des appareils avec un système Linux. Voici ce que l'on sait sur cette menace.
AcidPour, qui est considéré comme une variante du malware AcidRain, est, ce que l'on appelle un "data wiper", c'est-à-dire un malware dont l'unique but est de détruire les données présentes sur l'appareil infecté. Autrement dit, le malware AcidPour est destiné à effectuer des actes de sabotages. D'ailleurs, AcidRain a été utilisé dans le cadre d'une cyberattaque contre le fournisseur de communications par satellite Viasat, ce qui avait eu un impact important sur la disponibilité des services en Ukraine et en Europe.
Le malware AcidPour quant à lui, a été identifié par Tom Hegel, chercheur en sécurité chez SentinelLabs, et il a été téléchargé depuis l'Ukraine le 16 mars 2024. Il présente plusieurs similitudes avec AcidRain, notamment au sein des chemins pris pour cible sur les machines infectées. Néanmoins, les deux malwares ont uniquement 30% de code source en commun. AcidPour pourrait être une variante beaucoup plus évoluée et puissante qu'AcidRain, grâce à la "prise en charge" de la destruction de données sur une plus grande variété d'appareils.
AcidPour est un malware destructeur de données capable de s'attaquer à des équipements réseau, notamment des routeurs, mais aussi des appareils avec une distribution Linux embarquée (Linux x86). Par exemple, il pourrait s'agir de cibler des NAS dont le système est basé sur Linux, car le malware s'intéresse aux chemins de type "/dev/dm-XX.
Sur X (ex-Twitter), Rob Joyce, directeur de la cybersécurité de la NSA, affiche une certaine inquiétude vis-à-vis de ce logiciel malveillante : "Il s'agit d'une menace à surveiller. Mon inquiétude est d'autant plus grande que cette variante est plus puissante que la variante AcidRain et qu'elle couvre davantage de types de matériel et de systèmes d'exploitation.
Enfin, sachez que SentinelLabs a partagé un échantillon de ce malware sur VirusTotal, et vous pouvez le retrouver sur cette page publique.
Si vous déployez la solution GLPI dans votre entreprise, vous devez effectuer un suivi régulier des mises à jour. En effet, des mises à jour sont publiées régulièrement, et au-delà d'apporter de nouvelles fonctionnalités, certaines d'entres elles corrigent des failles de sécurité. Mais, alors, comment effectuer la mise à jour de GLPI ? Sachez que dans ce tutoriel, nous allons apprendre à mettre à jour GLPI !
Dans le cas présent, nous allons effectuer une mise à jour de GLPI 10.0.10 vers GLPI 10.0.12, qui justement, est une mise à jour de sécurité. Il s'agit de l'installation d'une mise à jour mineure, mais à chaque fois, les précautions à prendre sont identiques. Pour installer la version 10.0.14, qui est la dernière version en date, la procédure est identique.
Pour suivre les mises à jour de GLPI, vous pouvez consulter cette page :
Remarque : si vous envisagez d'effectuer une mise à jour majeure sur votre serveur GLPI, par exemple, pour passer de GLPI 9.5 à GLPI 10, vérifiez au préalable si les extensions que vous utilisez sont bien prises en charge par la nouvelle version. Si vous êtes dans ce cas, sachez que le plugin Fusion Inventory est pris en charge uniquement jusqu'à la version 10.0.3 de GLPI. Ensuite, vous devez passer sur l'agent GLPI officiel, qui est un fort de Fusion Inventory.
II. Quelle est ma version de GLPI ?
Pour savoir quelle version de GLPI vous utilisez, vous devez vous connecter sur l'interface Web de GLPI, puis cliquez sur votre avatar en haut à droite. Dans le menu qui apparaît, cliquez sur "À propos". Une fenêtre va apparaître et elle indique explicitement la version de GLPI que vous utilisez. Avant la version 10 de GLPI, la version était indiquée en bas à droite de la fenêtre.
III. Activer le mode maintenance de GLPI
GLPI 10 intègre un mode maintenance que vous pouvez activer avant d'effectuer la mise à jour. Ceci évite que les utilisateurs ou les techniciens cherchent à utiliser GLPI pendant cette période.
A partir de la ligne de commande de votre serveur GLPI, positionnez-vous dans le répertoire d'installer de GLPI (ici "/var/www/glpi") et exécutez la commande suivante :
cd /var/www/glpi
sudo php bin/console glpi:maintenance:enable
Si vous retournez sur GLPI, en mode web, vous allez obtenir ce message :
Même si le mode maintenance est actif, vous pouvez accéder à GLPI en précisant ceci dans l'URL :
Une fois la mise à jour effectuée, nous verrons comment désactiver ce mode maintenance.
IV. Sauvegarder les données
Avant de mettre à jour GLPI, vous devez impérativement sauvegarder vos données. S'il s'agit d'une machine virtuelle, vous pouvez utiliser votre outil de sauvegarde habituelle pour déclencher une sauvegarde avant de procéder à la mise à jour GLPI. Par ailleurs, si c'est une machine virtuelle, vous pouvez aussi utiliser un snapshot pour revenir en arrière facilement.
En complément, suivez les étapes ci-dessous, car ceci fait partie du processus de mise à jour de GLPI (notamment pour les données). En local sur le serveur GLPI, nous allons pouvoir sauvegarder les données et la base de données de l'application.
A. Sauvegarder la base de données
Pour commencer, nous allons sauvegarder la base de données de GLPI à l'aide de l'utilitaire mysqldump. Il est inclus nativement avec MySQL, et MariaDB.
Vous devez vous connecter à votre serveur et ouvrir une console en ligne de commande. Pour ma part, il s'agit d'un serveur sous Linux, donc la connexion est établie en SSH.
Si vous ne vous souvenez plus du nom de votre base de données, connectez-vous à votre instance MySQL :
mysql -u root -p
Indiquez le mot de passe root de MySQL. Puis, listez les bases de données :
show databases;
Pour ma part, la base de données s'appelle "db23_glpi". Désormais, nous allons sauvegarder cette base de données.
La commande ci-dessous permet de se connecter à l'instance MySQL en tant que root (vous pouvez, en principe, utiliser le compte utilisateur dédié à GLPI si vous en avez créé un) pour effectuer la sauvegarde de la base de données "db23_glpi". En sortie, cette sauvegarde donnera lieu au fichier "/home/glpi_adm/backup_db23_glpi.sql" (soit dans le "/home" de l'utilisateur avec lequel je suis connecté sur le serveur).
La sauvegarde sera plus ou moins longue en fonction de la quantité d'informations stockées dans votre base de données.
Vérifiez que le fichier de sauvegarde a bien été créé :
B. Sauvegarder les données
Dans les fichiers de GLPI, au-delà des scripts PHP et d'autres fichiers relatifs au bon fonctionnement de l'application en elle-même, il y a aussi vos données.
En effet, le répertoire "files" contient les documents ajoutés en tant que pièce jointe dans les tickets, tandis que le répertoire "plugins" contient les extensions que vous avez ajoutées à votre GLPI. En complément, les répertoires "config" et "marketplace" sont également importants.
Par précaution, vérifiez que les répertoires suivants soient bien présents (et qu'ils ne sont pas vides) : files, plugins, config et marketplace. Les fichiers "config_db.php" et "glpicrypt.key" du répertoire "config" sont particulièrement précieux.
ls -l /home/glpi_adm/backup_glpi/
V. Mettre à jour GLPI
A. Supprimer la version actuelle
Nous n'allons pas altérer la base de données de GLPI, mais nous allons supprimer le répertoire de la version actuelle. Par exemple, si votre GLPI est installé dans le répertoire "/var/www/glpi/" du serveur Web, c'est ce dossier que vous devez supprimer. Ceci permet de laisser la place libre pour la future version de GLPI.
Voici la commande à exécuter :
sudo rm -Rf /var/www/glpi/
B. Télécharger GLPI
À partir du GitHub officiel de GLPI, vous devez copier le lien de l'archive tar.gz correspondante à la version que vous souhaitez installer. Dans cet exemple, c'est la version 10.0.12 qui sera installée.
Puis, à partir de la ligne de commande, initiez le téléchargement avec la commande wget :
cd /tmp
wget https://github.com/glpi-project/glpi/releases/download/10.0.12/glpi-10.0.12.tgz
Une fois que c'est fait, décompressez l'archive tar.gz :
tar -xzvf glpi-10.0.12.tgz
Une fois l'archive décompressée, vous obtenez un dossier nommé "glpi" qui contient l'ensemble des fichiers de cette nouvelle version.
Vous devez déplacer ce dossier vers la racine de votre site web GLPI. Pour ma part, ceci revient à déplacer le dossier "glpi" vers "/var/www/glpi". Ce qui donne :
sudo mv glpi /var/www/glpi
Quand c'est fait, vous pouvez passer à la suite.
C. Récupérer vos données
La prochaine étape consiste à récupérer vos données. Vous savez celles contenues dans les répertoires "files", "plugins", "config" et "marketplace". Ainsi, nous allons récupérer ces dossiers à partir de "/home/glpi_adm/backup_glpi/" (emplacement de la sauvegarde créée précédemment) vers le répertoire "/var/www/glpi/".
Puis, nous allons modifier les permissions sur les données du répertoire "/var/www/glpi" pour que l'utilisateur "www-data", utilisé par Apache2, soit propriétaire :
sudo chown -R www-data:www-data /var/www/glpi/
D. Effectuer la mise à jour de la base de données GLPI
Voilà, vous y êtes ! C'est le moment de mettre à jour GLPI ! Enfin, la base de données, car en soi la mise à jour des fichiers est déjà effectuée !
Si vous accédez à l'interface de votre GLPI, vous allez tomber sur une page qui liste l'ensemble des prérequis et à la fin de cette page, il y a un bouton nommé "Upgrade" qui permet de déclencher la mise à jour.
Mais, l'éditeur de GLPI recommande plutôt d'effectuer la mise à jour à partir de la ligne de commande. Pour cela, vous devez continuer à utiliser la console de votre serveur (via une connexion SSH, par exemple).
Commencez par exécuter la commande ci-dessous pour vérifier les prérequis :
cd /var/www/glpi
sudo php bin/console glpi:system:check_requirements
Ceci permet de s'assurer que votre serveur dispose bien de tous les prérequis nécessaires pour accueillir GLPI. En principe, ce sera le cas, car GLPI était déjà installé. Dans la console, nous avons un statut pour chaque prérequis (comme en mode web).
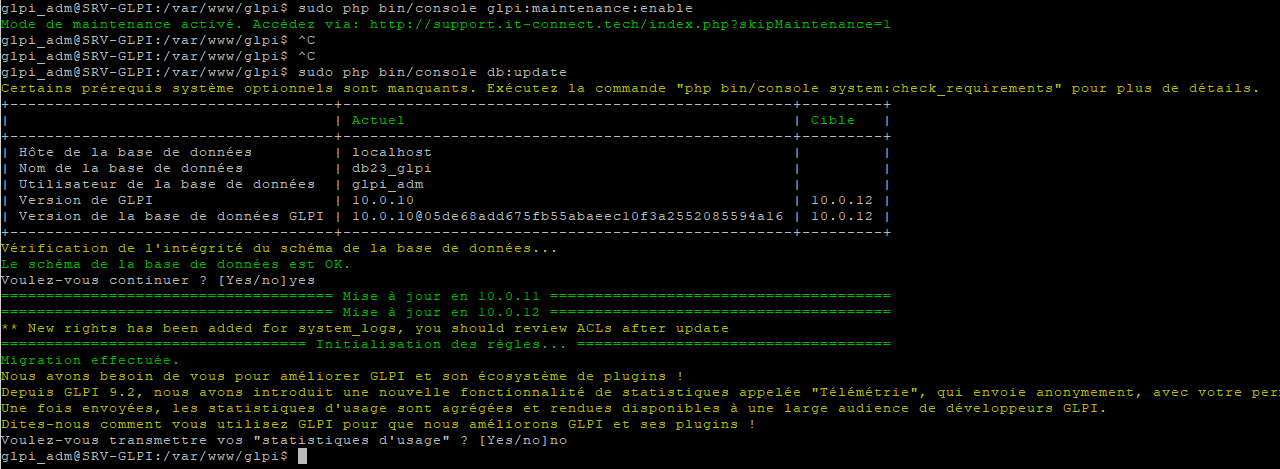
Si tout est bon, vous pouvez lancer la mise à jour de la base de données GLPI avec cette commande :
sudo php bin/console db:update
Laissez-vous guider par la ligne de commande et vous devrez répondre à une ou deux questions par "yes" ou "no". Voici un exemple sur mon serveur :
Quelques secondes plus tard, la mise à jour est effectuée ! La console retourne le message "Migration effectuée" en vert, ce qui est plutôt positif. Connectez-vous à votre GLPI pour vérifier que tout fonctionne.
La mise à niveau étant terminée, vous devez supprimer ce fichier par sécurité :
sudo rm /var/www/glpi/install/install.php
Si vous utilisez des plugins, vous devez également vérifier leur état et éventuellement les mettre à jour (si nécessaire) à partir du menu "Configuration" puis "Plugins", ou via la Marketplace si vous l'avez activée.
Enfin, vous pouvez désactiver le mode maintenance de GLPI :
cd /var/www/glpi
sudo php bin/console glpi:maintenance:disable
GLPI a été correctement mis à jour de la version 10.0.10 à la version 10.0.12 :
VI. Conclusion
En suivant minutieusement cette procédure, vous devriez être en mesure de mettre à jour l'application GLPI sur votre serveur, que ce soit pour installer une version mineure ou une version majeure. Personnellement, j'ai utilisé cette méthode pendant plusieurs années et je suis toujours parvenu à mettre à jour l'application.
N'hésitez pas à laisser un commentaire sur cet article si vous avez une question ou si vous souhaitez apporter des précisions supplémentaires.
À chaque fois que nous souhaitons visualiser le contenu d'un répertoire sous Linux (ou tout système UNIX-like), nous utilisons spontanément "ls" ou l'une de ses variantes avec des paramètres. La commande "ls" est l'une des premières commandes que nous apprenons en bash et elle est, sans contredit, l'une des plus utilisées quotidiennement par un administrateur système.Il existe pourtant une alternative moderne à "ls", un utilitaire nommé "exa" qui comprend des fonctionnalités beaucoup plus riches que son ancêtre qui a été introduit dans les années 1960 sous Multics, puis UNIX. Lorsque vous aurez essayé "exa" qui offre un affichage beaucoup plus riche, vous aurez du mal à vous en passer !
Les administrateurs Linux les plus aguerris auront peut-être un alias du type "ls -GAhltr" (-G : ne pas afficher les groupes dans une longue liste | A : ne pas lister les . et .. implicites | h : affichage "human-readable" | l : utiliser un format de liste longue | t : trier en selon le moment de création, le plus récent en premier ; r : utiliser ordre inverse lors du tri) pour personnaliser l'affichage et mieux classer l'information en sortie. On conviendra aisément que l'accumulation d'un tel nombre de paramètres est non seulement laborieux, mais peut aussi être difficile à déchiffrer pour un novice. Avec "ls", la sortie est très condensée, notamment pour les types de fichiers et les permissions, si bien qu'on préfère souvent utiliser "-grep" pour afficher uniquement ce qui nous intéresse... C'est ici que la commande "exa" devient particulièrement utile.
Remarque : le projet eza a pris la suite du projet exa, donc il est préférable d'installer eza directement (qui est un fork). En suivant ce lien, vous pourrez accéder au dépôt du projet exa.
II. Qu'est-ce que exa et comment l'installer ?
Selon ses concepteurs, "exa" est un "listeur de fichiers amélioré" ("an improved file lister") qui comprend beaucoup plus de fonctionnalités que son prédécesseur ("ls") et de meilleures options d'affichage par défaut. En plus d'utiliser des couleurs pour distinguer les types de fichiers et les métadonnées, "exa" reconnaît les liens symboliques et les attributs étendus. Il peut également afficher en mode "tree" et il s'intègre avec Git. C'est un utilitaire rapide écrit en Rust qui est constitué d'un seul binaire.
Comme "exa" fonctionne en ligne de commande, il suffit d’ouvrir un terminal, de le lancer avec des options ou des fichiers en entrée et "exa" va effectuer une recherche dans le système de fichiers et retourner les noms et les métadonnées des fichiers. Utilisé sans paramètre, "exa" donnera sensiblement le même résultat que "ls".
Avant de donner quelques exemples d'utilisation de "exa" , voyons comment l'installer pour les trois grandes familles de distributions Linux :
Debian et dérivées :
apt install exa
Fedora et dérivées :
dnf install exa
openSUSE :
zypper install exa
III. Exemples d'utilisation d'exa
Lister des fichiers est la seule fonction de la commande "exa" et, en cela, elle respecte la philosophie d'UNIX : "Write programs that do one thing and do it well". Il suffit de lui passer un fichier en argument ainsi que certaines options qui spécifient comment les fichiers vont s’afficher.
Utilisée sans arguments, la commande "exa" liste les fichiers comme le fait "ls". Si nous exécutons ls -lah(long / all / human-readable), nous obtenons, sans surprise, la sortie suivante :
ls -lah
Les mêmes paramètres utilisés avec "exa" donnent la sortie suivante :
exa -lah
exa --long --all --header
Tout devient ainsi beaucoup plus lisible et facile à identifier grâce à la coloration syntaxique et l’ajout d’en-têtes aux colonnes (dans "exa", -h signifie header).
Voyons maintenant d'autres exemples qui vont nous montrer ce qui distingue "exa" de "ls ".
Si vous souhaitez faire afficher la sortie sur une seule ligne, il suffit d'utiliser le paramètre -1 :
exa -1
exa --oneline
Pour faire afficher les répertoires en mode "tree", c'est très simple avec "exa" parce que le paramètre --tree vient nativement avec la commande :
exa -T
exa --tree
Bien sûr, comme c'est le cas avec "ls", vous disposez aussi d'une option de récursivité. Dans l'exemple suivant, elle est combinée à --long :
exa --long --recurse
exa -lR
L'exemple précédent montre également que la commande "exa" s'intègre à Git. Ici, on voit qu'elle souligne et met le README.md en surbrillance pour le repérer plus facilement.
Avec le paramètre --grid, vous obtenez une sortie semblable à celle que vous auriez pour "ls" :
exa --grid
exa --G
La commande devient plus intéressante avec l'option --across qui va faire le tri à l'horizontal (voir les fichiers numérotés) :
exa --across
exa -x
"exa" dispose aussi d'options de filtrage, en voici deux exemples :
exa --long --sort=name
exa -l -s=name
exa --long --sort=date
exa -l -s=date
D'autres options de tri sont disponibles comme :
size : taille des fichiers
ext : extensions des fichiers
mod : date de modification des fichiers
acc : dernière date d'accès aux fichiers
inode : tri des fichiers par inodes
type : tri des fichiers par type (fichier, répertoire, socket, lien symbolique)
IV. Conclusion
Dans ce tutoriel, nous avons découvert la commande "exa" qui se veut un remplacement moderne de "ls" qui existe depuis plus de 50 ans. "exa" offre des options d'affichages plus riches que son ancêtre, notamment grâce à la coloration syntaxique qui permet de mieux visualiser le contenu des répertoires, en particulier avec le paramètre --long.
Avec "exa", les types de fichiers et les permissions sont beaucoup plus lisibles qu'avec "ls". Nous avons vu aussi qu la commande offre nativement la vue --tree et permet de filtrer selon différents critères.
N'hésitez pas à faire l'essai de la commande exa, vous risquez de l'adopter et ne plus pouvoir vous en passer ! Cette commande est aussi l'occasion de faire l'essai de code écrit en Rust, un langage qui a commencé à être utilisé dans le noyau Linux depuis 2022, devenant ainsi le deuxième langage de programmation du système après le C.
Pour avoir plus de détails sur la commande, consultez le site officiel d'exa à l'adresse suivante :
Spinning YARN, c'est le nom associé à une campagne de cyberattaques qui a pour objectif de compromettre les instances Cloud sous Linux dans le but de déployer des logiciels malveillants. Les solutions ciblées : Docker, Redis, Apache Hadoop et Atlassian Confluence. Faisons le point.
D'après les chercheurs en sécurité de Cado Security, un groupe de cybercriminels cible les serveurs Cloud, soit en tirant profit de mauvaises configurations, ou en exploitant une faille de sécurité présente dans une version vulnérable. Plus précisément, les pirates ciblent Docker, Redis, Apache Hadoop ainsi que la solution Atlassian Confluence en exploitant la faille de sécurité CVE-2022-26134.
Dans un article de blog, Chris Doman, cofondateur et directeur technique de Cado Security, précise : "Les attaques sont relativement codées en dur et automatisées, de sorte qu'elles recherchent des vulnérabilités connues dans Confluence et d'autres plateformes, ainsi que des erreurs de configuration bien connues dans des plateformes telles que Redis et Docker."
Si l'on prend l'exemple de Docker, les attaquants ciblent Docker Engine API par l'intermédiaire d'une requête Web, dans le but de parvenir à exécuter du code sur l'hôte sur lequel sont exécutés les containers. Cado Security donne pour un exemple un conteneur basé sur Alpine Linux, sur lequel les cybercriminels sont parvenus à créer un montage bind pour le répertoire racine (/) du serveur hôte, vers le point de montage /mnt à l'intérieur du conteneur.
Lorsqu'une instance est compromise, les cybercriminels déploient un outil de cryptominage, ainsi qu'un reverse shell nommé Platypusqui leur assure à un accès persistant sur l'instance. Ainsi, ils peuvent utiliser cet accès pour déployer d'autres malwares par la suite. Ceci n'est pas sans rappeler les actions menées par les groupes TeamTNT et WatchDog, d'après les chercheurs en sécurité.
Docker, une cible à la mode
Cado Security alerte sur le fait que les cybercriminels s'attaquent à Docker de plus en plus fréquemment pour obtenir un accès initial sur un serveur ou un environnement complet.
"Il est bien connu que les points d'extrémité de l'API de Docker Engine sont souvent ciblés pour un accès initial. Au cours du seul premier trimestre 2024, les chercheurs de Cado Security Labs ont identifié trois nouvelles campagnes de logiciels malveillants exploitant Docker pour l'accès initial, dont celle-ci.", peut-on lire dans le rapport.
Ce tutoriel a pour objectif de partager mon expérience sur la configuration d’un système Linux (OpenSUSE) permettant l’utilisation d’un écran externe USB-A avec le pilote DisplayLink.
Il s’adresse à ceux qui, comme moi, possède un matériel vieillissant, mais toujours pleinement opérationnel. Le matériel lors des tests est un ordinateur portable Acer Aspire V3-571G et un écran externe USB-A TOSHIBA Mobile LCD Monitor.
Le système d’exploitation est openSUSE Leap 15.5 et/ou Tumbleweed. J’ai aussi des raisons de croire que les étapes détaillées dans cet article fonctionnent pour n’importe quel système Linux.
Tout d’abord, je remercie les personnes suivantes sans qui je n'aurais pas pu réussir :
Commençons par évoquer deux notions importantes pour bien comprendre la suite de ce tutoriel.
EDVI
L’EDVI (Extensible Virtual Display Interface) est un module kernel permettant la gestion de multiple moniteur.
DKMS
Le paquet DKMS (Dynamic Kernel Module Support) offre un support permettant l’installation de versions supplémentaires de modules de noyau. Il compile et installe dans l’arborescence kernel.
III. Installation et configuration
A. Prérequis
Le pilote DisplayLink consiste en deux composants :
Module kernel EDVI kernel
Paquet DisplayLink
Le paquet DisplayLink nécessite le paquet DKMS pour son installation.
Afin d’éviter des dysfonctionnements et avant de démarrer l’installation d’EDVI et de DisplayLink, installer préalablement les paquets suivants :
zypper install libdrm-devel kernel-source
B. Installation du paquet EDVI
Nous allons installer les différents composants, tour à tour, en commençant par le paquet EDVI.
Ajoutez le repository de mbrugger (note : la commande est en une seule ligne) :
Le paquet dkms est déjà présent dans un repository, il suffit de l’installer avec la commande suivante :
zypper install dkms
D. Redémarrer le système
À partir de ce point et pour une bonne prise en compte de l’installation des composants par le système, redémarrez la machine.
E. Installation du pilote DisplayLink
Désormais, penchons nous sur l'installation du pilote DisplayLink, pour la prise en charge graphique. Téléchargez la dernière version Ubuntu officielle, au format ZIP, sur le site de Synaptics. Voici le lien :
Ajoutez les privilèges d’exécution au fichier « .run » :
chmod +x displaylink-driver-5.8.0-63.33.run
Puis, exécutez le fichier « .run » avec les privilèges nécessaires :
sudo ./displaylink-driver-5.8.0-63.33.run
L’installation devrait se faire sans incident. Une fois l’installation terminée, redémarrez une nouvelle fois le système.
IV. Testez : branchement de votre écran
Après le redémarrage, branchez votre écran pour effectuer un test. Celui-ci devrait être reconnu automatiquement par votre système. Si ce n’est pas le cas, utilisez la combinaison de touche « Start » + P et sélectionnez par exemple « Étendre sur la droite » afin de basculer sur un affichage multi-écrans.
Note : La touche « Start » est l’équivalent de la touche Windows.
Dans ce tutoriel, nous allons apprendre à effacer un disque de manière sécurisée sur une machine Linux, à l'aide des commandes "dd" et "shred".
Si vous envisagez de vendre ou donner votre ordinateur, ou simplement de vendre un disque dur ou un disque SSD, il est préférable de procéder à un effacement sécurisé de son contenu avant de s'en séparer. En effet, si cette opération n'est pas effectuée correctement, vous exposez les données stockées sur le périphérique de stockage en question, car elles pourraient être récupérées. Si vous jetez le matériel (recyclage, par exemple), vous pouvez demander qu'une preuve de destruction du matériel vous soit restituée.
Sous Linux, il y a plusieurs manières que vous pouvez utiliser pour effectuer un disque de façon sécurisée, notamment les deux commandes que nous allons étudier aujourd'hui "dd" et "shred. Mais, il en existe probablement d'autres...
Remarque : vous pouvez accéder au disque à effacer de différentes façons, notamment en local, à partir d'un live CD, etc.
II. Effacer un disque avec dd
Avant d'effacer un disque, vous devez commencer par identifier votre cible c'est-à-dire le disque que vous souhaitez effacer. Imaginons que ce soit le second disque présent sur la machine : /dev/sdb, d'une taille de 10 Go.
Vous pouvez lister vos disques avec cette commande :
fdisk -l
Voici un aperçu du disque qui sera utilisé pour cette démonstration :
Ensuite, pour exécuter un effacement sécurisé de ce disque, saisissez cette commande :
dd if=dev/urandom of=/dev/sdb
Cette commande va remplir l'intégralité du disque "/dev/sdb" à l'aide de données aléatoires puisque nous utilisons "/dev/urandom". Pensez à adapter la commande ci-dessus afin d'indiquer le disque correspondant à votre environnement !
Ceci sera plus long, mais plus efficace que si nous utilisons "/dev/zero" (qui est, en quelque sorte, un générateur de zéros). Toutefois, les deux sont possibles.
dd if=dev/zero of=/dev/sdb
Dans les deux cas, vous devez patienter pendant l'opération. Ce processus peut être très long. Tout dépend de la taille du disque et des performances de votre machine. Quand ce sera terminé, le message suivant apparaîtra :
dd: écriture vers '/dev/sdb': Aucun espace disponible sur le périphérique
Voici un exemple :
Bien entendu, rien ne vous empêche de lancer ce processus plusieurs fois : ce ne sera que mieux.
III. Effacer un disque avec shred
La commande shred est également très efficace pour effacer définitivement un fichier ou un disque. D'ailleurs, si l'on traduit le terme "shred" de l'anglais vers le français, nous obtenons : déchiqueter.
Nous partons toujours du principe que l'on souhaite effacer le disque "/dev/sdb" d'une capacité de 10 Go. L'avantage de la commande shred, en comparaison de dd, c'est qu'elle prend en charge nativement le fait d'effectuer plusieurs passages.
Voici comment effectuer 5 passages pour effacer notre disque :
shred -n 5 -vzf /dev/sdb
En complément, voici des explications sur les options "vzf" utilisées ci-dessus :
-v : mode verbeux, ce qui permet de suivre la progression dans la console.
-z : ajouter des zéros à la fin du processus d'effacement, c'est une façon de masquer ce que vient de faire shred
-f : forcer l'opération, ce qui implique de modifier les permissions si nécessaire
En fait, si nous décidons d'effectuer 2 passes (-n 2), il y aura en vérité trois passes : 2 avec des valeurs aléatoires, et 1 avec des zéros (option -z). Ceci est visible sur l'image ci-dessous :
Le mode verbeux est très intéressant pour suivre l'évolution du processus d'effacement. Ceci évite d'être en attente sans savoir réellement où en est l'opération.
Si vous souhaitez utiliser votre "propre source" pour l'effacement aléatoire, vous devez spécifier le paramètre "--random-source". Ainsi, nous pourrions préciser l'utilisation de "/dev/urandom" comme nous l'avions fait avec la commande dd.
Voilà, il ne reste plus qu'à patienter ! Attention à ne pas se tromper de disque !
IV. Conclusion
Grâce à l'utilisation de ces commandes et après avoir effectué plusieurs passes, vous pouvez envisager de vous séparer sereinement de votre disque ! Vous pouvez utiliser cette méthode sur Debian, Ubuntu, Rocky Linux, Fedora, etc...
Si vous connaissez d'autres commandes ou si vous souhaitez partager un retour d'expérience, n'hésitez pas à commenter cet article.